目的:澄清 2026 年 4 月 LLM + AI 编码工具在项目级代码(50 万行 / 中度游戏规模)审计场景下的真实能力边界,为团队技术决策提供依据。
核心结论:LLM 在局部辅助开发上已经非常好用,但在全局代码审计上目前没有成熟方案。两者是本质不同的任务,不应混淆。
一、概念对齐:辅助开发与代码审计的本质差异
在评估 LLM 的代码能力之前,我们必须先澄清一个常见的认知误区:辅助开发和代码审计是两个完全不同的任务,对模型的要求有着本质区别。
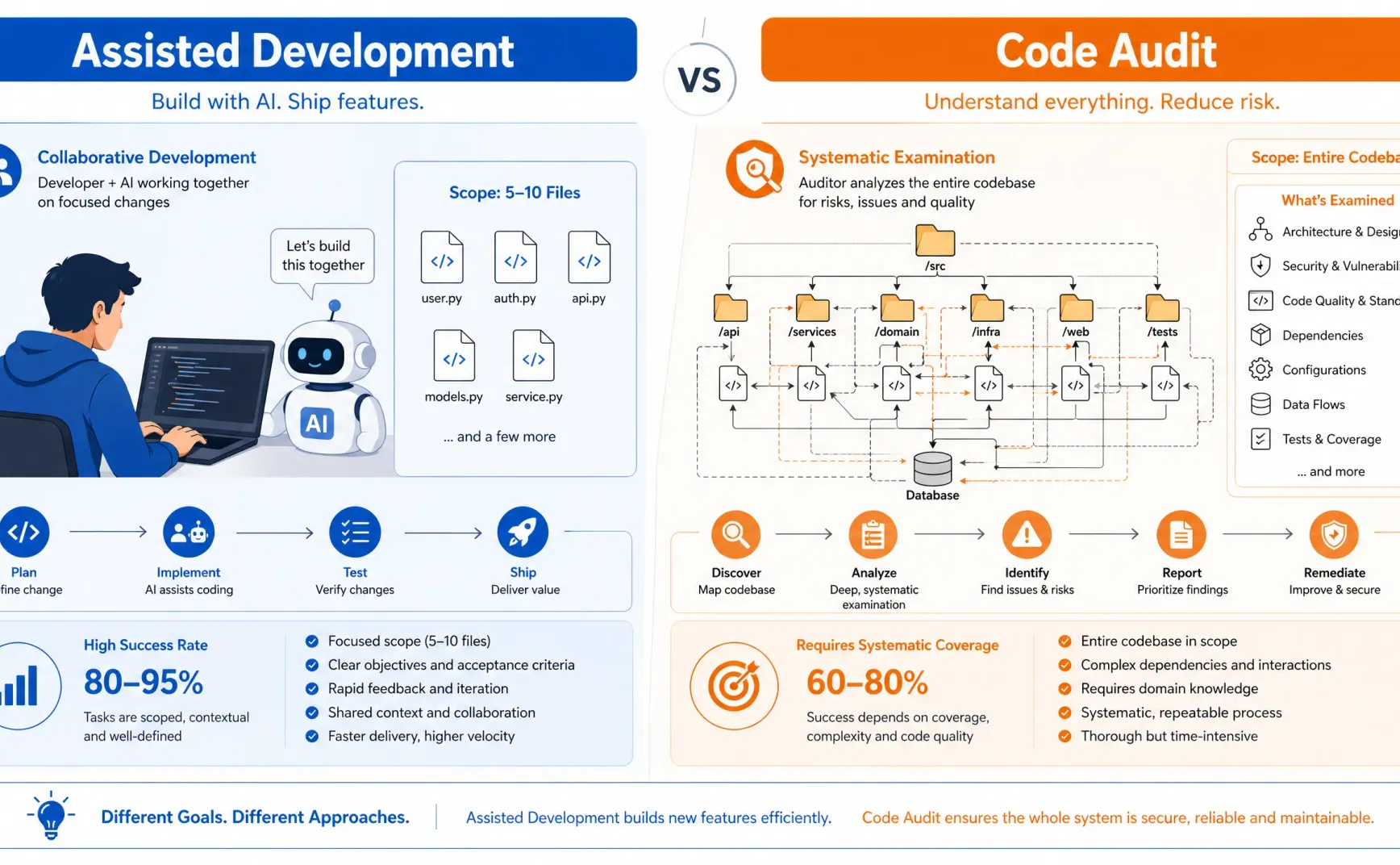
辅助开发场景中,开发者已经明确知道要做什么——修复一个已知的 bug、实现一个新功能、重构某个模块。模型的任务是理解当前任务涉及的 5-10 个文件,在开发者的引导下完成具体的代码变更。这是一个人在环路中、容错率高、范围可控的协作过程。
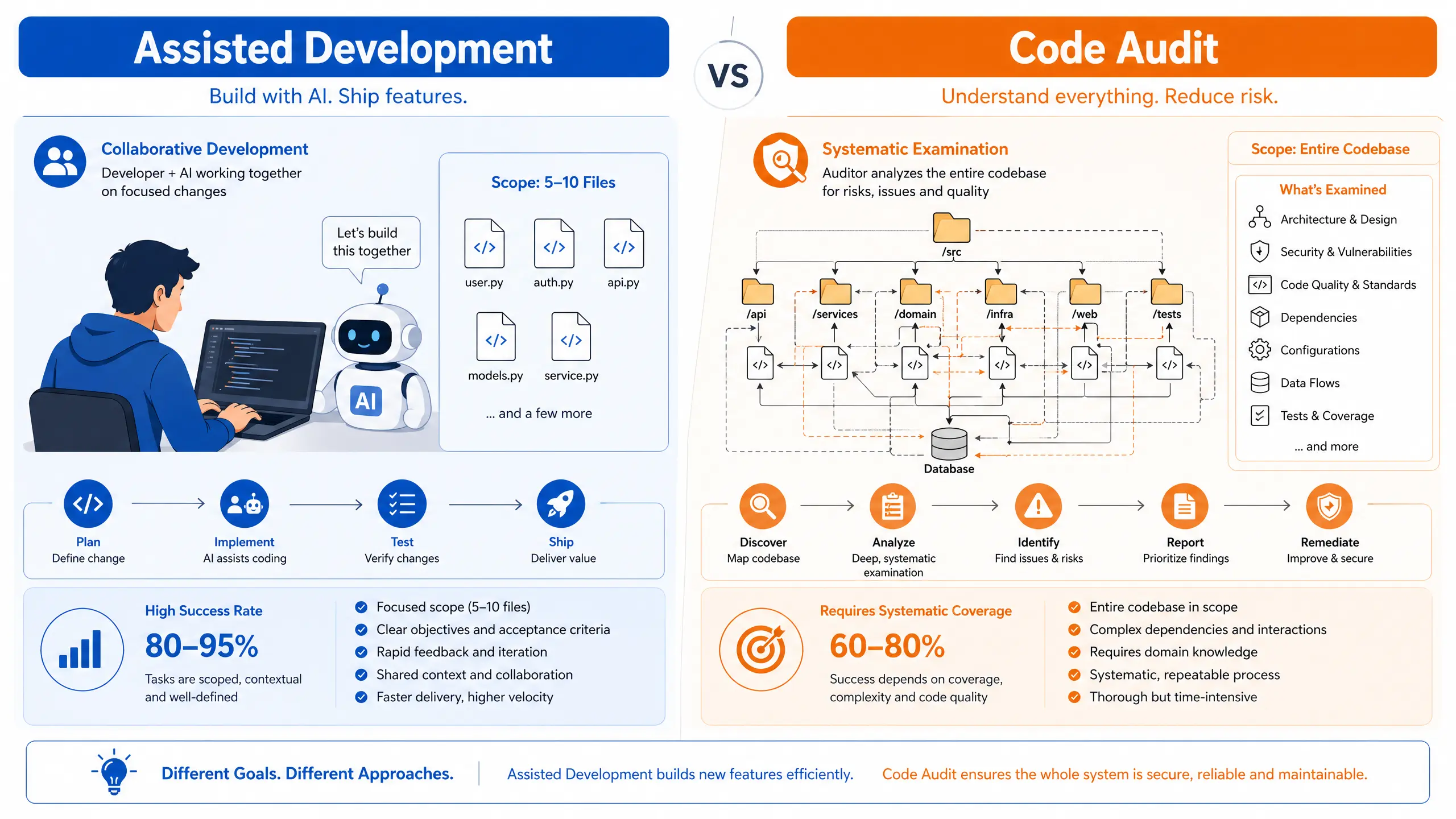
代码审计则完全不同。审计员面对的是一个完整的代码库,需要在没有明确问题描述的情况下,系统性地发现潜在缺陷——可能是架构设计层面的问题,可能是跨模块的隐含依赖,也可能是边界条件的遗漏。这要求对整个代码库建立全局理解,进行跨模块推理,并且不能有遗漏。容错率极低:漏审一个关键问题就意味着审计失败。
| 维度 | 辅助开发(已成熟) | 代码审计(未成熟) |
|---|---|---|
| 模型需要理解的范围 | 当前任务涉及的 5-10 个文件 | 整个代码库的全局架构和隐含关系 |
| 问题是否已知 | 是(开发者知道要做什么) | 否(需要模型自己发现问题) |
| 跨模块推理 | 偶尔需要,可人工引导 | 核心要求,必须自主完成 |
| 容错率 | 高(人在环,可随时纠正) | 低(漏审 = 审计失败) |
| 当前工具胜任度 | 高 | 低 |
市面上宣称“支持百万行代码库”的工具——Cursor、Augment、Sourcegraph Cody 等——解决的都是辅助开发问题。它们能索引百万行代码,让开发者在需要时检索到相关片段,但“索引”和“理解”是两回事。Sourcegraph 能索引 Google 的整个代码库,但没人会说它“理解”了 Google 的代码。这个区别至关重要。
二、结构性瓶颈:为什么 50 万行全局审计现在做不到
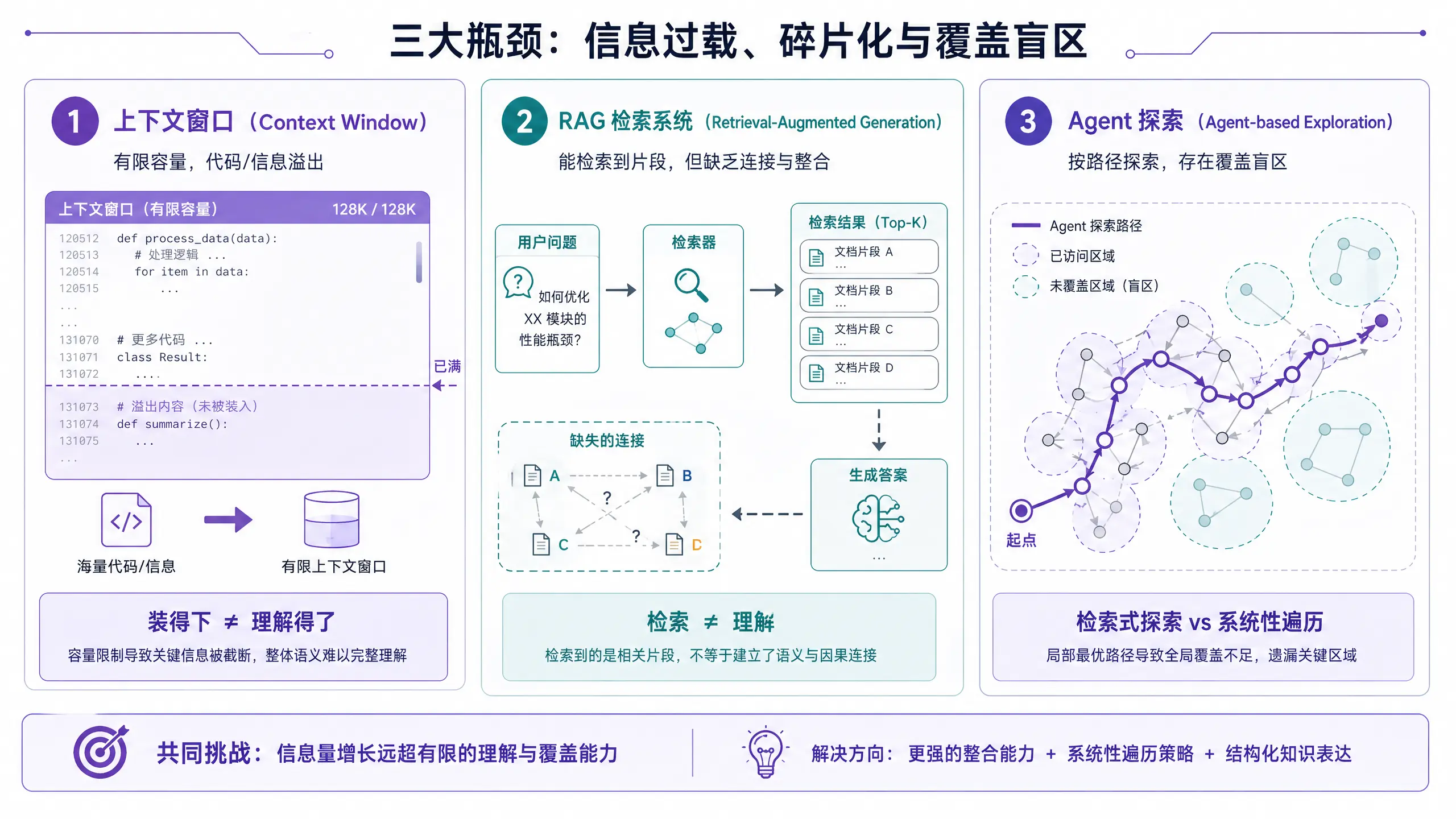
2.1 上下文窗口的悖论:装得下不等于理解得了
2026 年 4 月,主流模型的上下文窗口已经全面达到 1M tokens 级别。这是一个重要的技术突破:
| 模型 | 上下文窗口 | 发布/GA 时间 | 备注 |
|---|---|---|---|
| Claude Opus 4.7 | 1M tokens | 2026-04-16 GA | 标准定价 $5/$25 per MTok,无长上下文溢价 |
| Claude Opus 4.6 / Sonnet 4.6 | 1M tokens | 2026-03-13 GA(标准定价) | 此前 200K 以上有 2x 溢价,已取消 |
| Gemini 2.5 Pro | 1M tokens | 2025-06 GA | 200K 以上有 2x 溢价;2M 版本仍未 GA |
| Gemini 3 Pro | 1M tokens | 2026 | 默认 1M |
| GPT-5.4 | 1M tokens | 2026 | 超过 272K 有 2x 溢价 |