A widely circulated architectural approach in the AI community is leading countless teams astray.
TL; DR
If you're considering naming multiple AI Agents as "Product Manager," "Architect," and "Test Engineer," and having them pass summarized conclusions between each other like company departments—stop right there.
The problem isn't role labels themselves. It's the combination of role-as-constraint (agents refuse to cross boundaries) plus compressed handoffs (passing summaries instead of original artifacts). This pattern looks intuitive and seems logically sound, but it has fundamental engineering flaws.
More importantly, when Anthropic, OpenAI, and Google built their own Agent systems, not a single one adopted this specific combination.
This is not a coincidence.
What is the "Virtual Company" Architecture
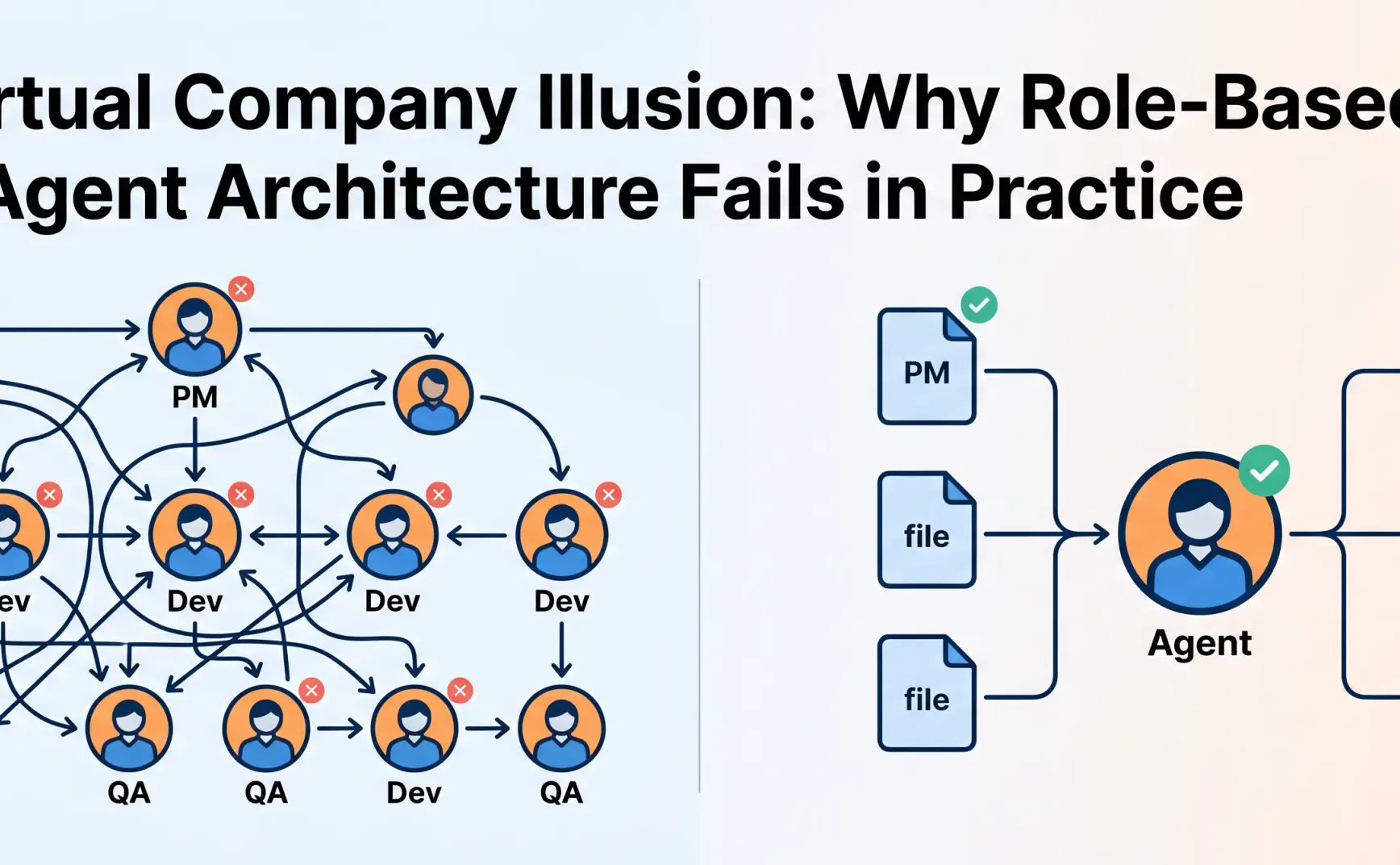
This metaphor refers to a class of multi-Agent design patterns widely popular in the community, known by different names across various frameworks and articles: role-based agents, virtual team, CrewAI-style division of labor, MetaGPT-style organization—this article collectively calls them the "Virtual Company" pattern.
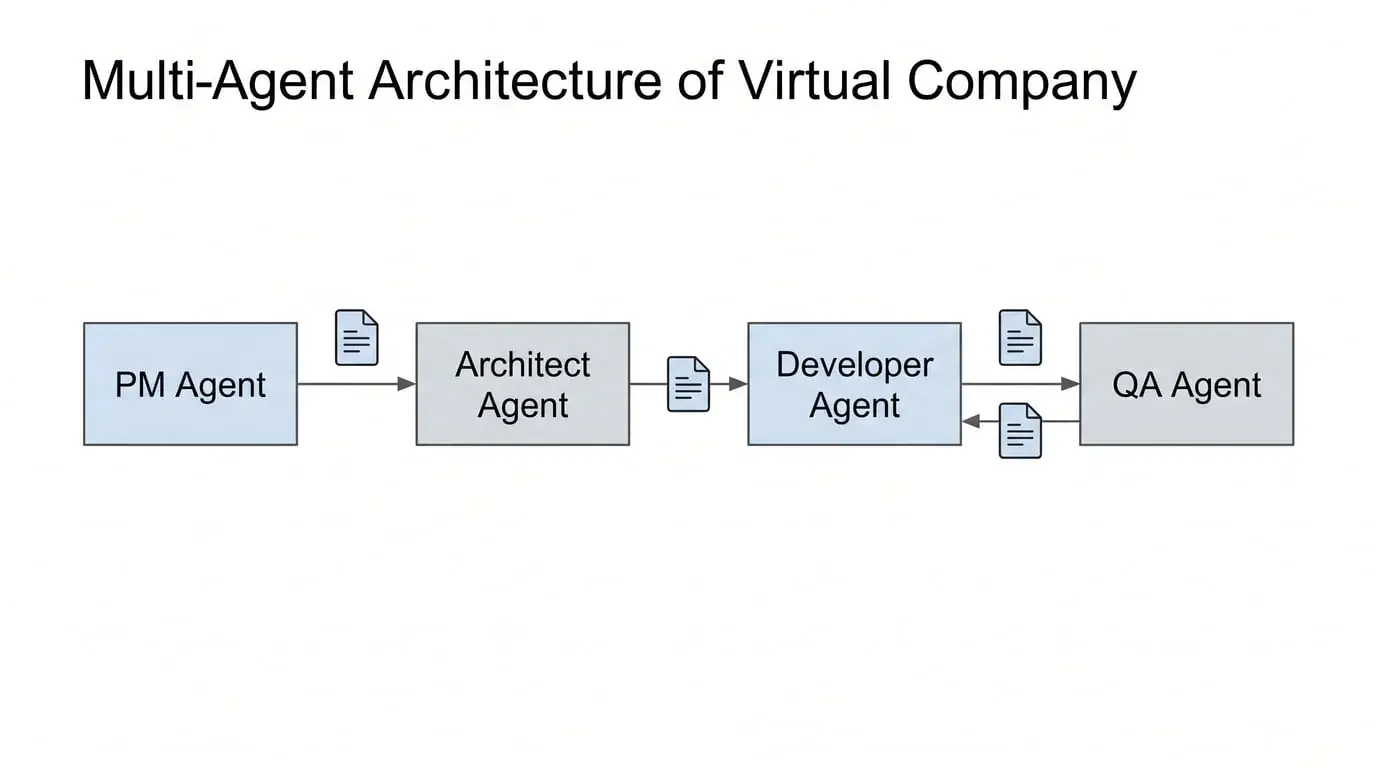
The core pattern is: decompose a complex task into multiple functions, with each Agent playing a role—PM handles requirements, Tech Lead handles architecture, Dev handles implementation, QA handles testing. Tasks flow between Agents like an assembly line.
This pattern looks great in diagrams. It satisfies human intuition about "division of labor and collaboration," and makes the concept of an "AI team" concrete and explainable. Frameworks like CrewAI have accumulated large user bases precisely because of this.
What this article actually criticizes: We're not opposing role labels or multi-Agent systems in general. The specific problem is role-as-cosplay combined with serial compressed handoffs—where agents are constrained by role boundaries AND information is compressed into summaries at each handoff. These two conditions together create the failure mode.
The problem is, it solves human bottlenecks, not AI bottlenecks.
Why This Analogy is Fundamentally Wrong
Humans need division of labor because:
-
Individual attention is limited; one person cannot process all information simultaneously
-
People have professional barriers; learning and switching costs are high
-
People need interfaces to coordinate with each other
But LLM characteristics are completely different:
-
The same model can write PRDs and code; there are no "professional boundaries"
-
The model's bottleneck is not attention breadth, but reasoning depth and information completeness
-
Models lack "culture" and "tacit understanding" to compensate for information loss
Labeling an Agent as "Product Manager" doesn't make it more professional—but it will make it refuse to cross boundaries. An Agent locked into a "Test Engineer" role might skip architectural issues entirely because they're "not within my responsibility." The most valuable reasoning often happens at boundaries, and the Virtual Company pattern systematically eliminates this possibility.
Role-playing creates false boundaries. This is the first problem.
The Second Problem: Information Dies in Transit
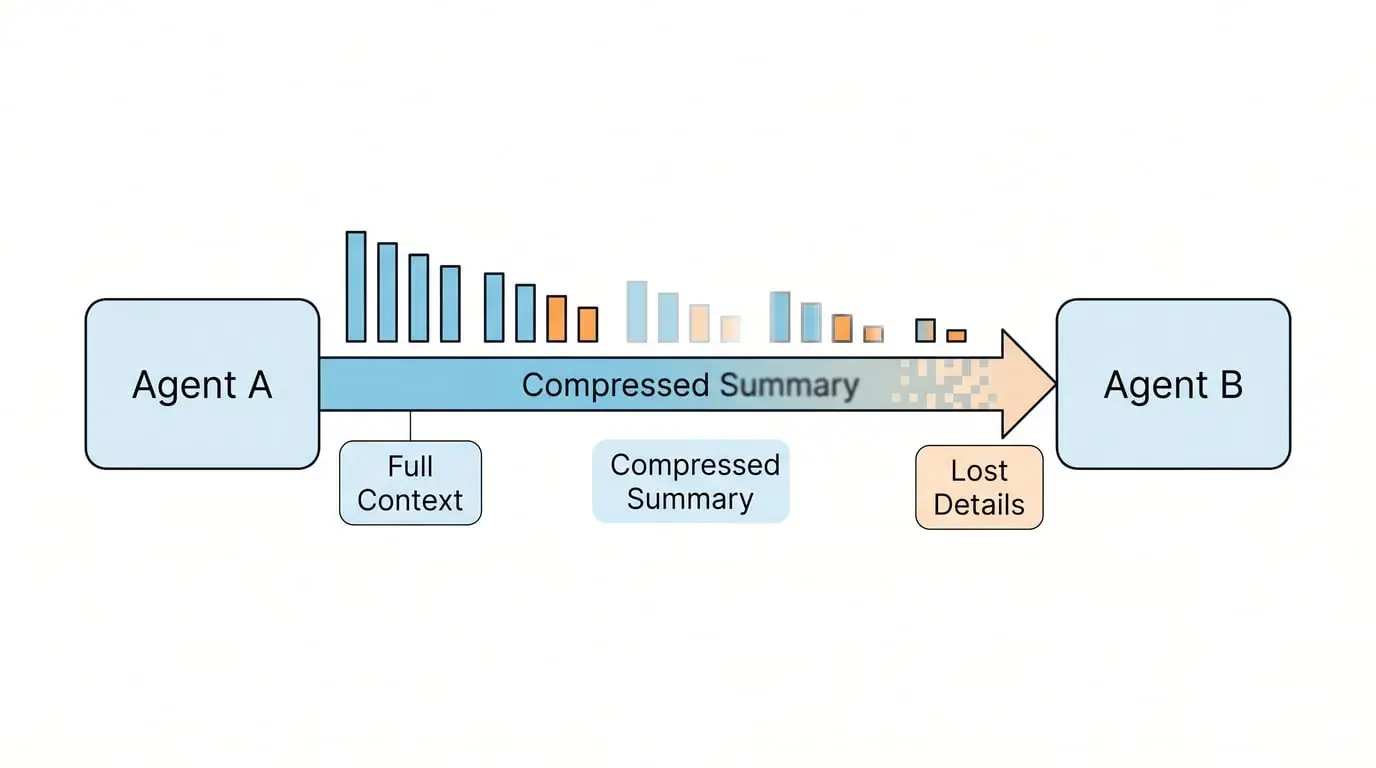
In the Virtual Company pattern, Agent A produces a document and passes it to Agent B.
This process transmits conclusions, not reasoning processes.
B receives the document, re-understands it, re-establishes context. Original intent decays, implicit assumptions are lost, and each handoff accumulates error. The longer the workflow, the more the final output becomes "locally correct but globally drifted"—each node seems reasonable, but the whole has deviated from the initial goal.
Human organizations compensate for this information loss through meetings, culture, and informal communication. Agents lack these mechanisms.
A common counterargument here: Don't the three vendors' solutions (progress.txt, spec files, runbooks) also "pass files"? What's the difference?
The difference lies in who writes, for whom, and how it's updated.
Virtual Company information flow is unidirectional handoff between roles: A finishes and hands to B, B never looks back, A doesn't know how B used the document. Information is compressed into conclusions, reasoning processes are lost, and the handoff is a breakpoint.
External state files are incremental logs of the same task: the executing entity appends to the same record at each checkpoint, and the next session reads the complete task history, not the previous "colleague's" output conclusions. The writer and reader are the same role, just at different times. Information isn't "compressed and passed"—it's "continuously accumulated."
The core distinction: passing original artifacts vs. passing summaries. Consider two systems with identical "Developer agent" roles:
-
System A: Developer agent reads
product-spec.mdv3.2 directly from shared storage -
System B: Developer agent receives a summarized requirements description from the PM agent
These look identical in architecture diagrams, but produce completely different results. System A preserves the complete reasoning chain; System B loses information at every handoff.
This difference determines whether the reasoning chain can remain continuous across sessions.
Massive tokens are wasted on "handoff documents" between Agents rather than actual reasoning. You get a system that simulates company behavior, not one that solves problems.
What the Three Vendors Actually Do
Notably, when Anthropic, OpenAI, and Google actually built their production-grade Agent systems, their engineering documentation contains almost no mention of "role-playing" or "departmental division of labor."
Anthropic: Context Engineering + Explicit State Files
Anthropic internally upgraded "Prompt Engineering" to "Context Engineering": the question isn't how to write a good prompt, but what token configuration best produces the desired behavior.
When building Claude Code and Research systems, their core challenge was: Agents must work in discrete sessions, with each new session having no memory of what happened before. Their metaphor is "shift workers"—each new shift worker arrives knowing nothing about the previous shift's work.
The solution isn't to have Agents play different roles, but:
-
claude-progress.txt: A cross-session work log that Agents update at the end of each session and read at the start of the next
-
Git history: As a state anchor, recording each incremental change
-
Initializer Agent: Runs only in the first session, establishes environment, expands feature list, writes runbook for all subsequent sessions
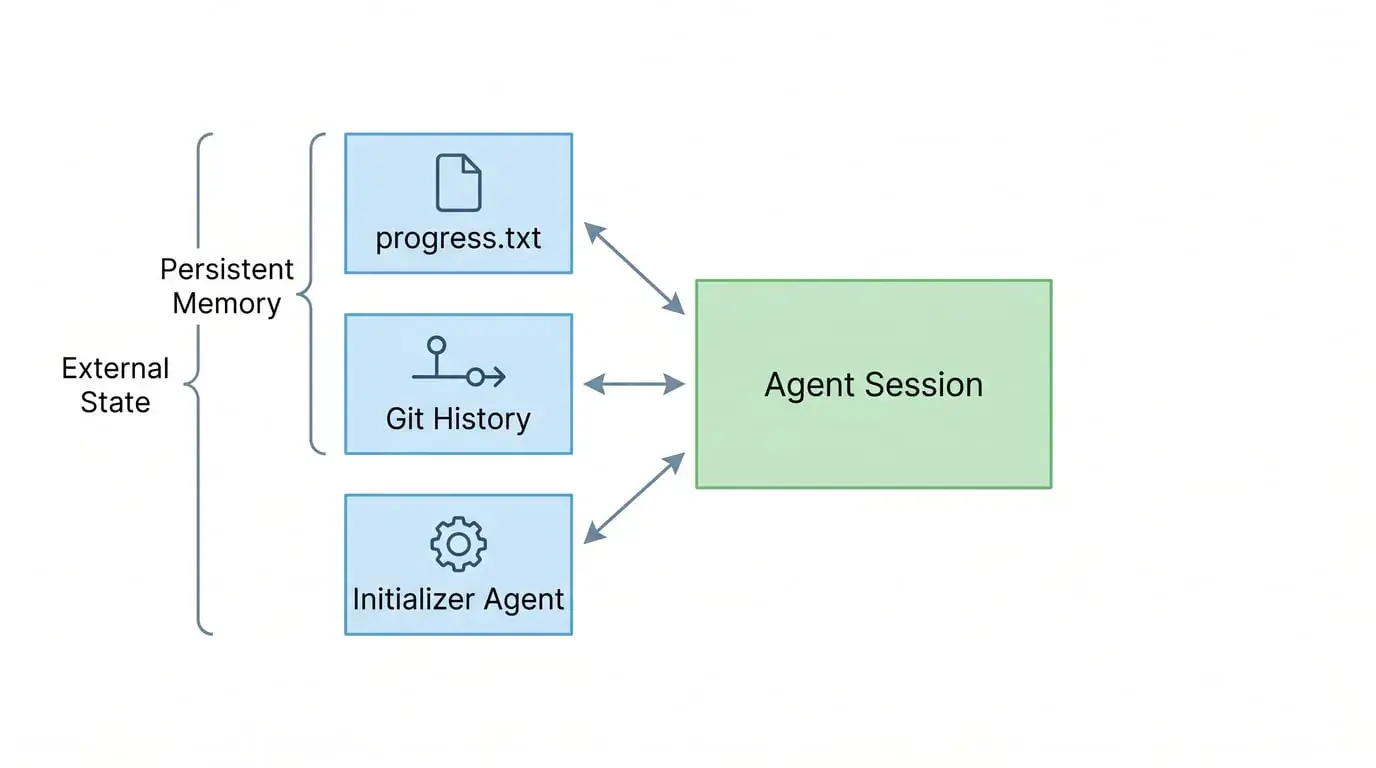
Key insight: Reasoning chain continuity doesn't rely on the model "remembering"—it relies on explicit external state as an anchor.
They also discovered that hardcoding "model capability assumptions" into the harness is dangerous. Sonnet 4.5 had "context anxiety"—it would wrap up prematurely near the context limit, so they added context reset to the harness. But Opus 4.5 eliminated this behavior, and the reset became dead weight. This shows: harnesses need to evolve with models; any "permanent solution" is just an engineering compromise for the current stage.
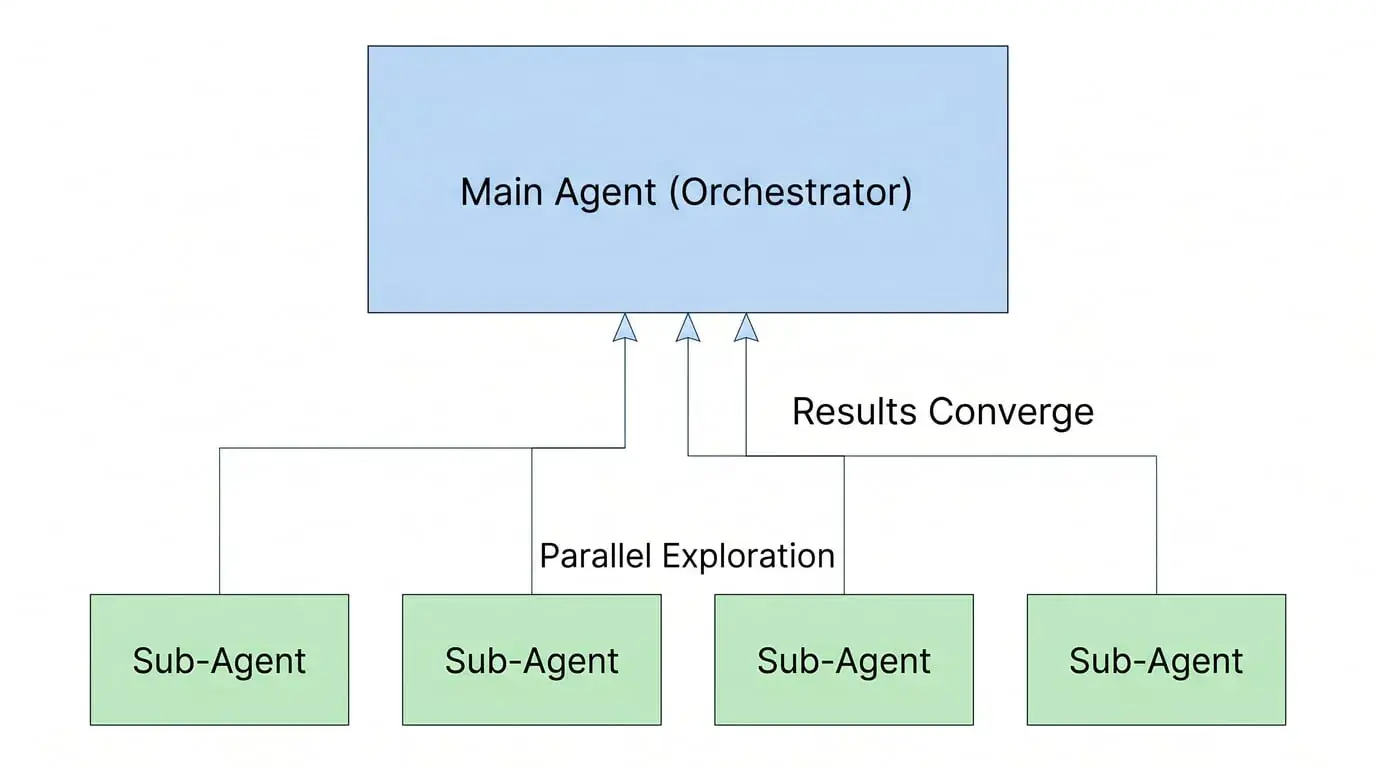
In their multi-Agent Research system, Anthropic's architecture is orchestrator-worker: one lead agent decomposes tasks and coordinates subagents, subagents explore different directions in parallel, and results flow back to the lead agent for synthesis. They found that token consumption itself explains 80% of performance variance—multi-Agent value isn't "division of labor," but using more tokens to cover a larger search space.
There's an easily confused point here: Anthropic's subagents also look like "division of labor," but the essence is completely different. Virtual Company is functional division—different roles undertake different job types, PM finishes and passes to Dev, Dev finishes and passes to QA, each role only handles one segment of the pipeline. Anthropic's subagents are functional parallelism—multiple agents of the same nature simultaneously search different directions, with no "next baton," and all results converge back to the same orchestrator for synthesis. The former is a relay race; the latter is casting multiple nets simultaneously.
OpenAI: Compaction + Skills + Structured Spec Files
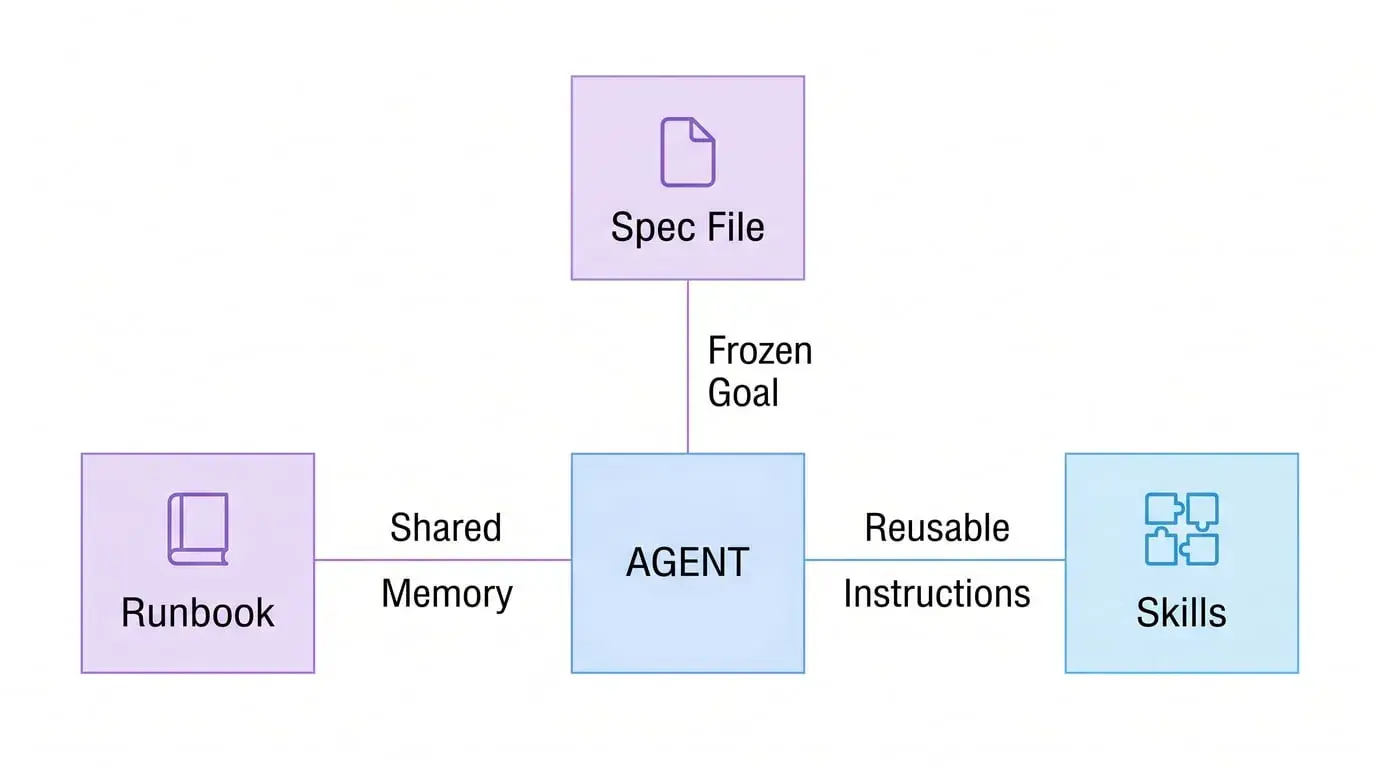
OpenAI's long-task principles are more direct: plan for continuity at the task's outset.
In their Codex experiments, engineers gave the agent a spec file (freezing the goal to prevent the agent from "making something impressive but directionally wrong"), had it generate a milestone-based plan, then used a runbook file to tell the agent how to operate. This runbook simultaneously serves as shared memory and audit log.
Result: GPT-5.3-Codex ran for approximately 25 hours uninterrupted, completing a full design tool while maintaining coherence throughout.
Server-side compaction as a default primitive, not an emergency fallback. In multi-step tasks, previous_response_id allows the model to continue working in the same thread rather than rebuilding context each time.
They also introduced the Skills concept—reusable, versioned instruction sets mounted into containers, giving agents stable operational specifications when executing specific tasks. This isn't a "role"—it's tools and operating procedures, fundamentally different things.
Google: 1M Context + Context-Driven Development
Google's direction is to hard-expand the window: Gemini's 1M token context is a clear differentiation strategy. Their logic is: techniques previously forced upon us—RAG chunking, discarding old messages—can be replaced by "just put it all in" with a large enough window.
But they admit this isn't enough. Google introduced the Conductor extension in Gemini CLI, with core thinking identical to Anthropic's: move project intent out of the chat window and into persistent Markdown files in the codebase. The philosophy: "Don't rely on unstable chat history; rely on formal spec and plan files."
Gemini 3 also introduced the Thought Signatures mechanism: saving key nodes of the reasoning chain in long sessions to prevent "reasoning drift"—the problem of logical inconsistency across long contexts.
What Are the Real Architectural Principles
From the engineering practices of all three, we can distill several common principles:
Reasoning chains cannot break—they can only fork and merge. The correct use of multi-Agent isn't a pipeline, but a main agent holding complete intent, with sub-calls to dig deep into specific sub-problems, results flowing back to the main agent, not passed to the next agent.
Explicit external state, not relying on model memory. progress.txt, git history, spec files, databases—the form doesn't matter; the principle is: key nodes of the reasoning chain must be externalized to persistent storage, not relying on the model "remembering" in the context window.
Multi-Agent value is parallel coverage, not division of labor. Anthropic Research system's conclusion is clear: performance improvement mainly comes from "spending more tokens," not from "more reasonable division of labor." Multi-Agent suits breadth-first tasks—scenarios requiring simultaneous exploration of multiple independent directions. Not suitable for scenarios requiring continuous reasoning and deep context dependence.
Another valid use case: context isolation to prevent task interference. Multi-Agent isn't just about search space coverage—it's also about preventing context pollution. When running 10 parallel feature developments, isolated agent sessions prevent information from one task bleeding into another. This isn't about "division of labor"—it's about information hygiene and maintaining clean boundaries between unrelated workstreams.
Verification Agents are challengers, not relay runners. If using multi-Agent for quality control, the correct design is to have one Agent specifically find problems with another Agent's work, not "pass work products." Adversarial verification, not pipeline handoff.
Tools are tools, not roles. What tools you give an Agent (bash, file read/write, search, code execution) matters far more than what label you give it. Tools determine what an Agent can do; role labels only constrain what it's willing to do.
Why Does the Virtual Company Pattern Remain Popular?
Because it's easy to explain.
"This Agent is PM, that one is QA"—anyone can understand that sentence. It satisfies human desire for AI system explainability, and management's imagination of "AI working like a team."
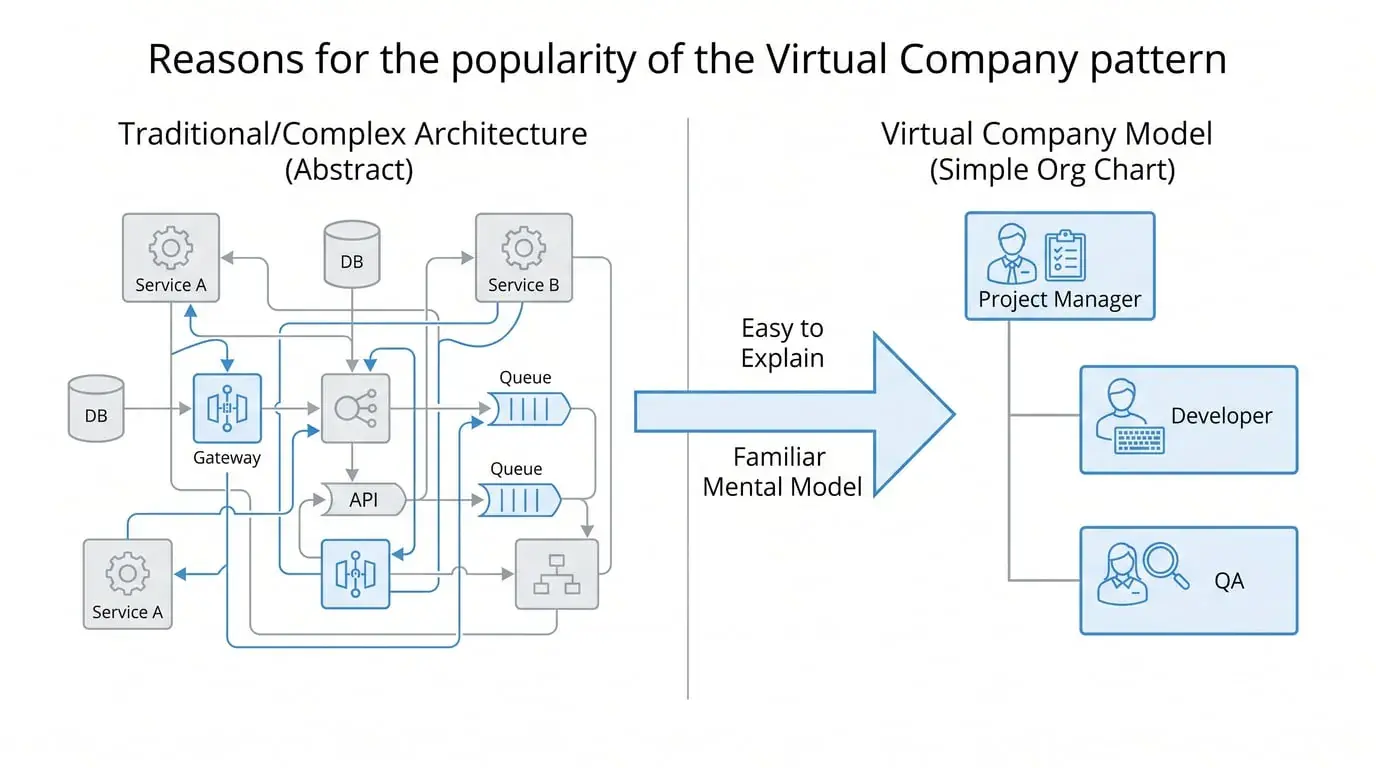
It's also easy to demonstrate. Draw it as a flowchart with departments, arrows, and handoffs—very intuitive.
But easy to explain and easy to demonstrate are different from engineering validity.
The deeper reason: most teams adopting this pattern haven't truly faced the problem of "context loss when passing between multi-Agents." Their tasks may not be complex enough, or the problem is masked by other factors. Only when task complexity rises and the system starts showing bizarre "locally correct but globally wrong" behavior does the problem surface.
Practical Recommendations
The best multi-Agent systems don't resemble companies. They're more like multiple drafts from a single thinker—the same brain unfolding reasoning across different dimensions, ultimately merging into a coherent conclusion.
From this principle:
Don't ask "how many Agents do I need"—ask "what is this task's information dependency structure."
The correct dimension for splitting is information structure, not role function. Ask: "Can this information be processed independently?" not "Who should be responsible for this work?"
If the task requires continuous reasoning with high context dependence (like writing a design document for a complex feature), single Agent + good context engineering usually beats multi-Agent.
If the task requires simultaneously exploring multiple independent directions (like researching 10 competitors' different modules at once), parallel multi-Agent is reasonable—each subagent's task is mutually independent, minimizing information loss cost. This is the reason behind Anthropic Research system's token volume explaining 80% of performance variance: it's not division of labor that makes it better, it's larger search coverage.
If you need to isolate unrelated tasks to prevent context pollution (like running multiple parallel feature developments), multi-Agent with isolated sessions makes sense—not for division of labor, but for information hygiene.
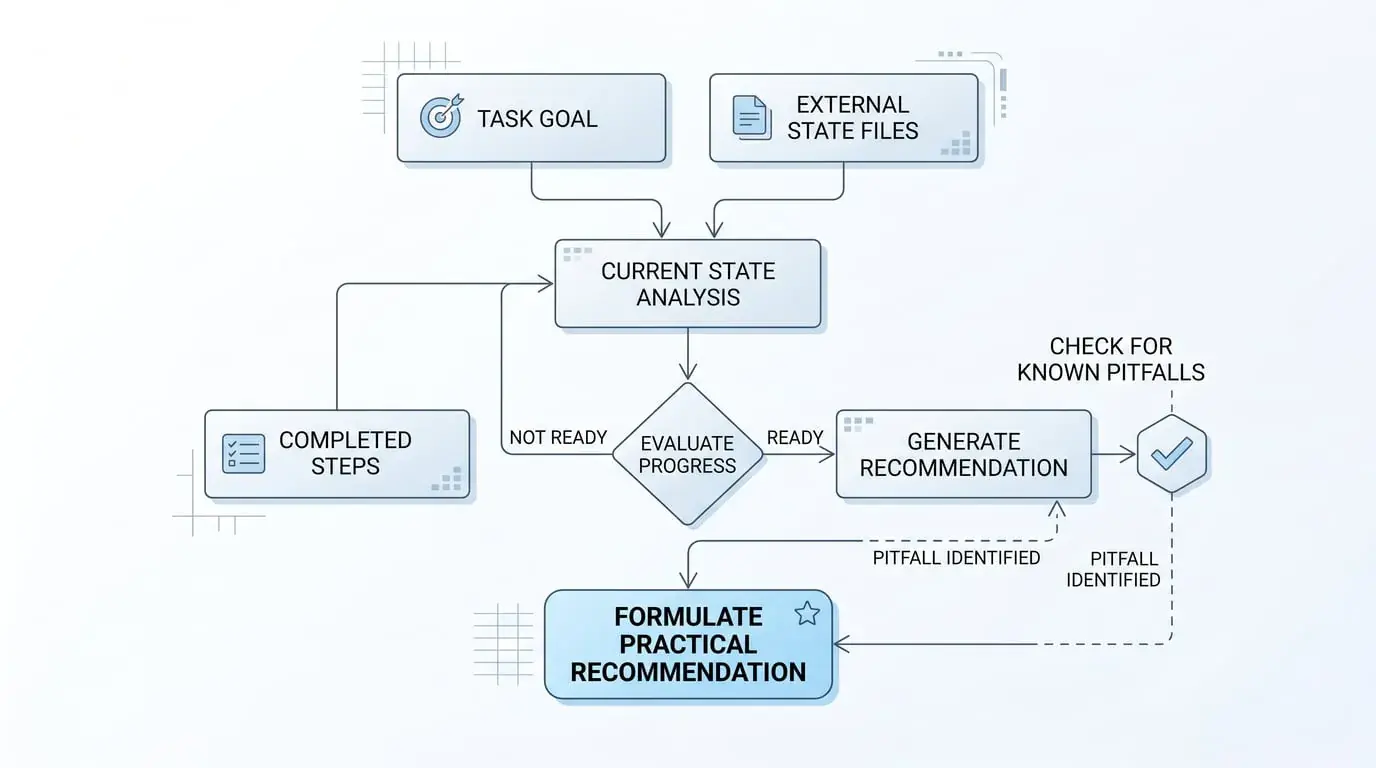
If the task spans multiple sessions, external state files are mandatory. An effective state file should contain four types of information:
-
Task goal (immutable, read at session start, prevents drift)
-
Completed steps (append, don't overwrite, preserve complete history)
-
Current state (overwrite, reflects latest progress)
-
Known pitfalls (append, avoid next session repeating mistakes)
Maintain these four types separately; together they form the complete context "the next you" needs.
If you do use role labels, use them as perspective switches, not capability constraints. A "Security Reviewer" role should indicate which lens to apply when examining code, not which parts of the codebase the agent is allowed to see. The role frames attention and priorities, not permissions or boundaries. When roles become constraints rather than perspectives, you've recreated the Virtual Company anti-pattern.
If adding verification, make the verification Agent's sole task finding problems, not "taking the baton to continue." Adversarial verification, not pipeline handoff.
When in doubt, prefer tools over agents. If a subtask is deterministic and can be encapsulated with clear inputs/outputs, make it a tool function rather than a separate agent. Tools are faster, more stable, easier to debug, and consume less context. Reserve multi-Agent architecture for tasks where the next step cannot be determined in advance and requires model reasoning.
Finally: model capabilities are rapidly improving; workarounds needed in today's harness may become dead weight in six months. Anthropic has already verified this—Sonnet 4.5's context anxiety disappeared in Opus 4.5, and the context reset designed for it immediately became useless code. Maintaining architectural evolvability is more important than choosing a "perfect architecture."
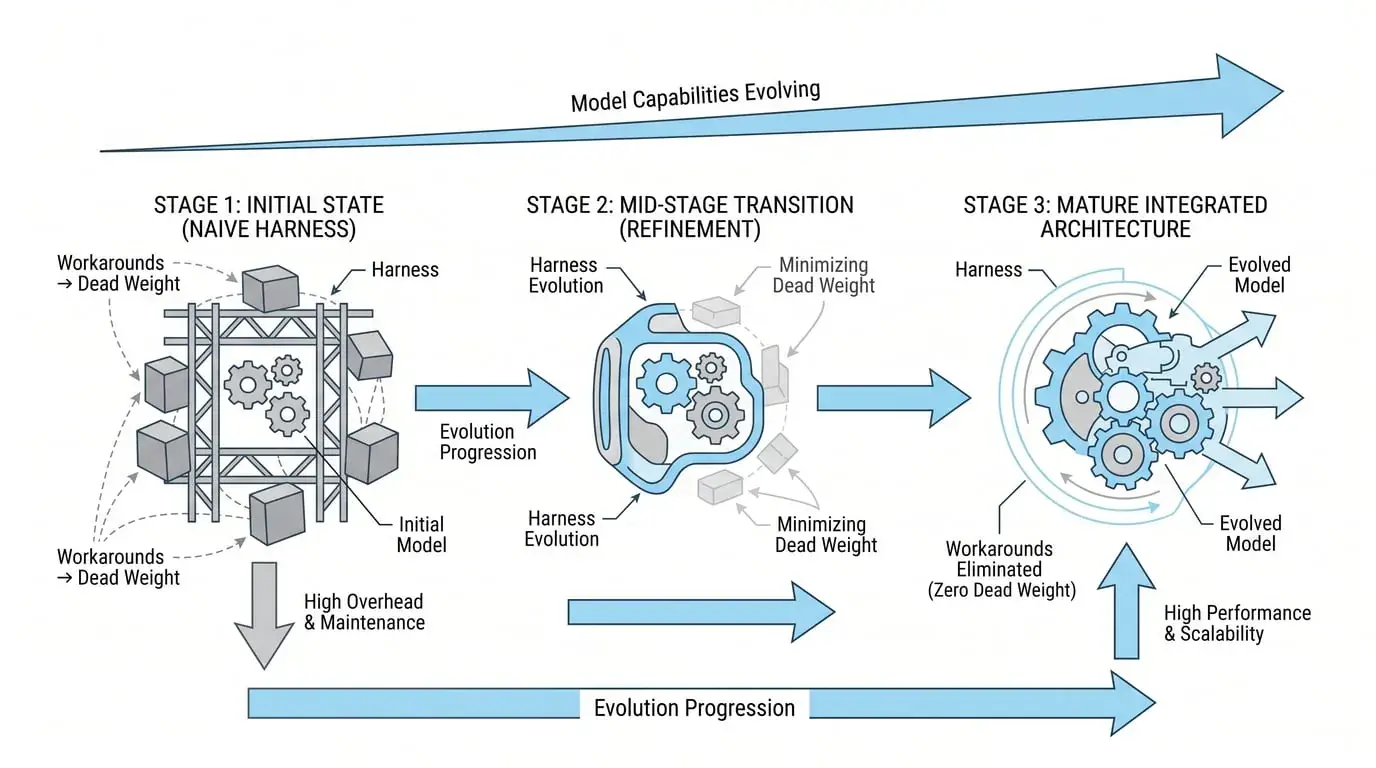
The Virtual Company is an illusion that feels good but is engineering-costly. Its true cost isn't direct failure, but causing your system to degrade in a hard-to-diagnose way as complexity rises—each node "appears to be working," but the whole is drifting.
By the time you discover the problem, the pipeline is already long.
References: Anthropic Engineering Blog (Building Effective Agents, Effective Context Engineering, Multi-Agent Research System, Effective Harnesses for Long-Running Agents, Managed Agents); OpenAI Developers Blog (Run Long Horizon Tasks with Codex, Shell + Skills + Compaction); Google Developers Blog (Architecting Efficient Context-Aware Multi-Agent Framework, Conductor: Context-Driven Development for Gemini CLI)