
每次切换 AI 模型,你要花多少时间重新让模型认识你?
我统计了一下,大概30-50分钟。但最烦的其实是那些信息散落各处,根本不知道去哪儿找——项目背景在某个对话里,禁止行为写在另一个地方,关系网络全凭印象重新描述。
这件事让我意识到:我对 AI 说过的所有上下文,都被困在了各个平台的记忆系统里。Claude 知道的,GPT 不知道。GPT 调教好了,换 Gemini 又要从头来。
这个问题不应该靠「不切换模型」来解决。
问题的本质
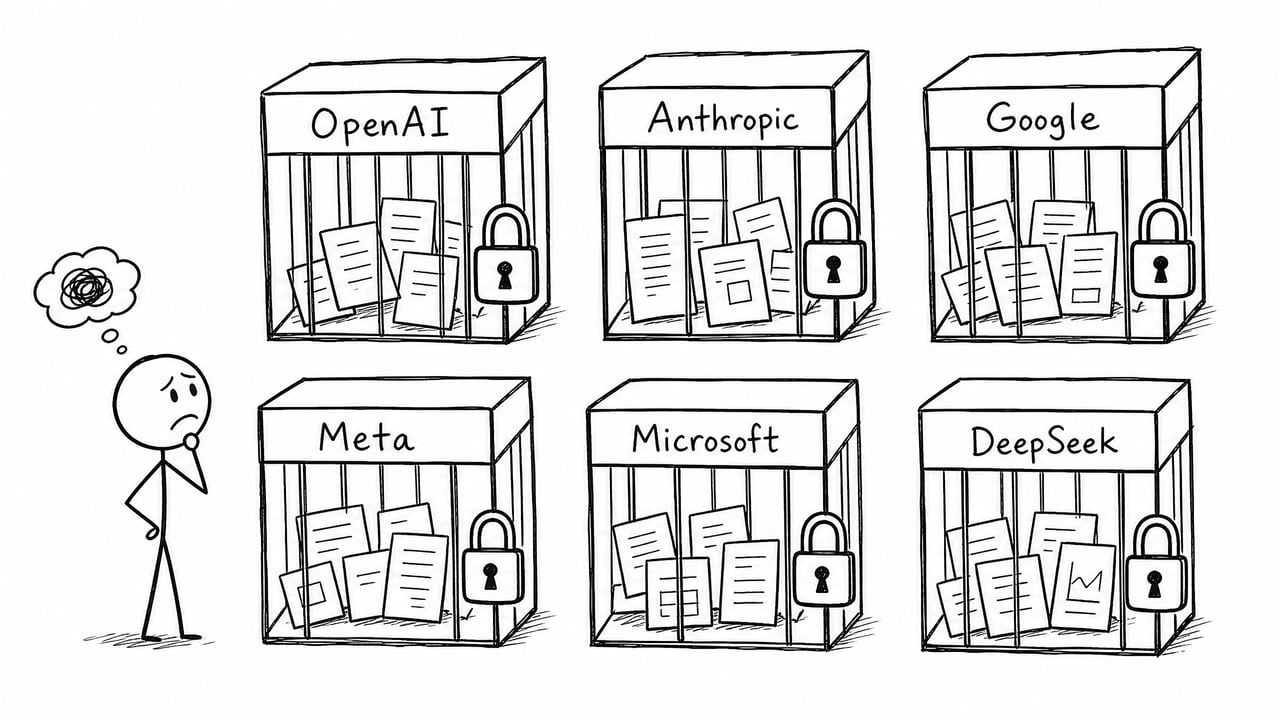
迁移麻烦只是表象,真正的问题是信息没有固定的家。
你用 Claude 积累的上下文,本质上是你的资产——你的工作方式、你的项目、你对 AI 的行为要求。这些东西应该属于你,存在你的本地,别锁在某个平台的数据库里。
我把这类信息叫做 Personal Context Asset(PCA,个人上下文资产)。
PCA 是什么
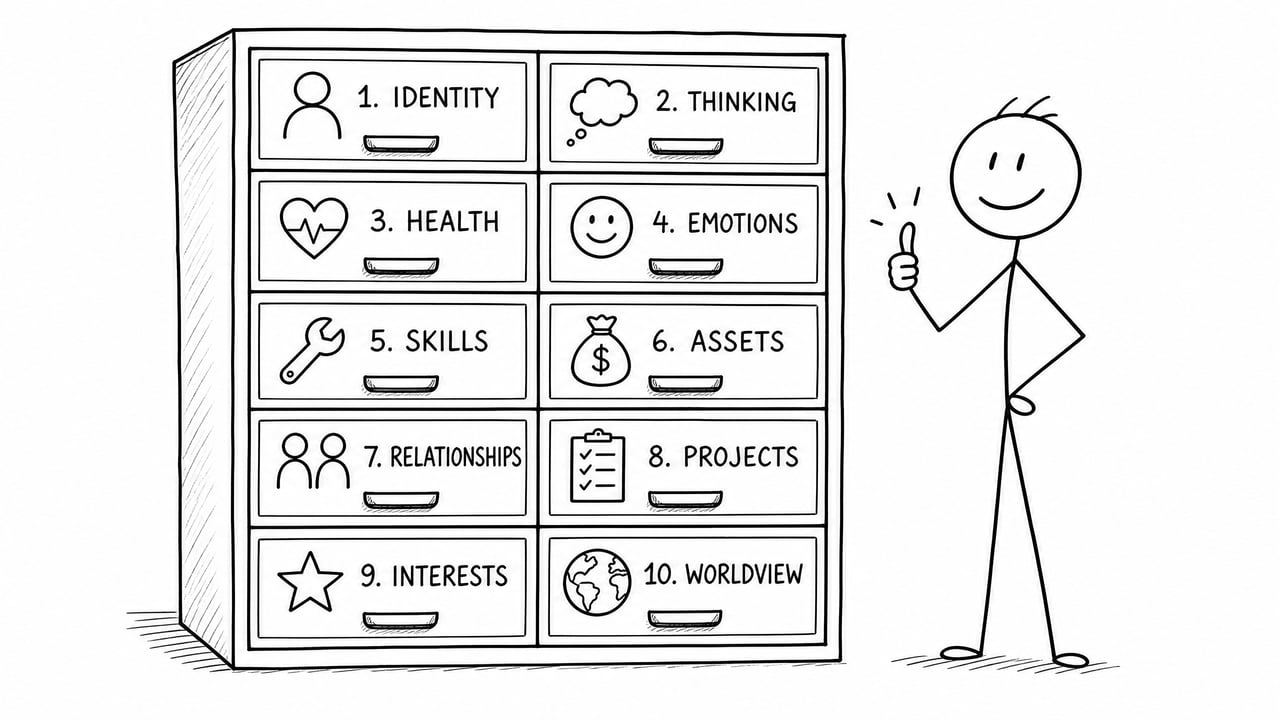
一组本地 Markdown 文件,覆盖一个人在 AI 语境下的完整上下文。
简历?自我介绍?都不对。它是让任意 AI 模型快速进入工作状态所需要的全部信息。
我把它设计成10个正交维度:
| 维度 | 核心问题 |
|---|---|
| D1 叙事身份 | 我是谁,怎么走到现在 |
| D2 认知操作系统 | 我怎么思考,对 AI 有什么强制要求 |
| D3 具身状态 | 我的身体和健康 |
| D4 情绪与心理 | 我的心理状态(可选) |
| D5 能力与专长 | 我能做什么,用什么工具 |
| D6 资产图谱 | 我拥有什么(产品、设备、代码库) |
| D7 关系网络 | 我和谁有关系 |
| D8 项目快照 | 我在做什么(3-12个月窗口) |
| D9 兴趣与审美 | 我喜欢什么,反感什么 |
| D10 世界观与志向 | 我相信什么,想去哪里 |
每个维度有更新频率(从月级到年级不等),有敏感级别标注。
分级披露
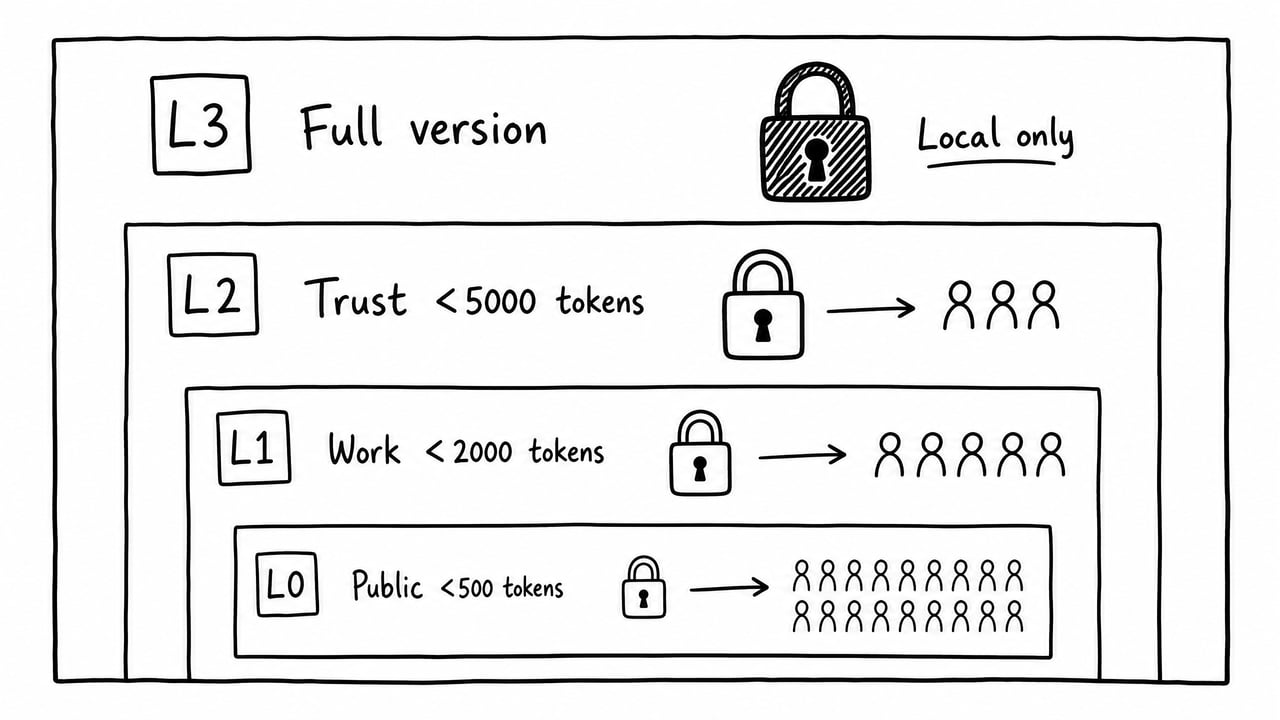
不是所有信息都适合给所有模型看。我设计了4个级别:
L0 公开版(<500 tokens):只有身份标签和行为规则,随意粘贴,没有任何敏感信息。
L1 工作版(<2000 tokens):加上项目背景、能力专长、工作关系。适合日常 AI 协作,可以安全发给任何商业 AI 服务。
L2 信任版(<5000 tokens):包含脱敏后的健康状态、资产信息、完整关系网络。适合长期使用的主力模型。
L3 全量版:原始数据,只存本地,永不外发。
最重要的部分:D2认知操作系统
10个维度里,D2认知操作系统最特殊。
其他维度记录的是“你是什么样的人”——你的背景、能力、项目、关系。但 D2记录的是**“你要求 AI 怎么工作”**。
这里存的是你对 AI 的强制约束——注意,这些是必须执行的规则,不只是偏好:
ai_hard_rules:
forbidden:
- "不说套话:禁止'很有意思''可能值得考虑'"
- "不主动生成docx/pptx,默认markdown"
- "不把兴趣/等候名单当需求,付钱才算需求"
required:
- "必须表态:这能不能成立,依据是什么"
- "方案给出2-3个路径并明确推荐"
这些规则粘贴进任何模型,立刻生效。不需要再花时间「调教」。
使用流程
建立(第一次,约15-30分钟)
-
把导出 prompt 粘贴进已积累上下文的模型
-
获得草稿,检查⚠️标记,删除不想保留的内容
-
填入模板,空白处标
【待填写】 -
按级别生成4个导出文件
迁移(每次切换模型,约2分钟)
-
打开
L1_work.md -
复制导入 prompt + 文件内容
-
粘贴进新模型第一条消息
-
验证:模型能否正确识别你的行为规则
维护(每月约5-10分钟)
更新 D3(健康)和 D8(项目快照)。每季度运行季度检视 prompt 扫描全部维度。
和平台 Memory 的关系
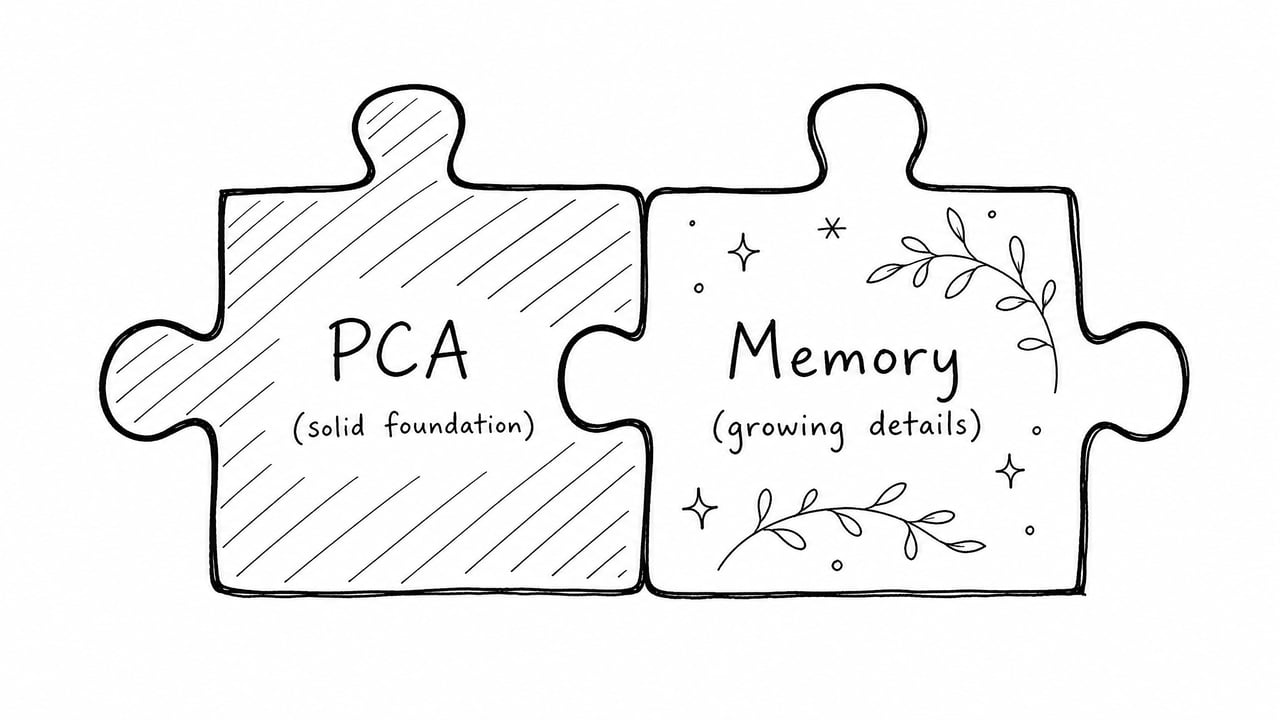
两者互补,各司其职。
平台 Memory(如 Claude 的记忆功能)负责增量细节——最近对话的具体内容、新发生的事。
PCA 负责结构化基线——跨模型、跨对话都稳定的核心上下文。
两者叠加,覆盖面最完整。
下载
所有文件开源,MIT 协议:
-
selfctx/ — 模型无关的完整文件夹,含 README、schema、6个 prompt、空白模板
-
selfctx.skill — Claude 用户专属,自动触发历史搜索和结构化导出
→ [GitHub:https://github.com/s87343472/selfctx】
如果你也在用多个模型,试试用导出 prompt 跑一遍。草稿出来之后你会发现,模型对你的了解比你以为的要多,但结构比你想象的要散。
把它收拢成一个文件,是值得做一次的事。