![[付费深度] YC新秀Coval:AI语音测试平台](https://images.quaily.com/olNkTLjabm3MM33iJJJ7xBNJD0klImCryfyDaISO1zs/rs:fill:868:536:1:0/f:webp/dpr:2/plain/https://static.quaily.com/media/dmr6spl9e.webp)
| 字段 | 内容 |
|---|---|
| 报告标题 | Coval估值体系重构:颠覆性技术催生周期反转,深度买入时机已至 |
| 分析产品 | Coval |
| 发布日期 | 2026年7月4日 |
| 报告受众 | AI Agent开发团队的技术决策者、专注于AI基础设施的早期风险投资人、以及寻求技术差异化优势的独立AI创业者 |
1. 执行摘要
Coval 是 Y Combinator (YC) 最新投资的初创项目,也是近期由顶级风投 Norwest 领投 2800 万美元 A 轮融资的平台。 在 AI Agent 泡沫退潮、市场开始追问“可靠性”而非“惊艳度”的当下,Coval 精准地切入了 AI 基础设施中最被低估也最致命的环节:部署前的自动化压力测试与生产环境的持续质量评估。
这不是又一个 LLM 封装应用,而是一个从底层重构 AI Agent 评估逻辑的基础设施。它用一种“自动驾驶测试”般的思维,模拟上万通包含口音、噪音甚至攻击性意图的通话,在 AI 客服、语音助手正式上线前就能识别出致命缺陷。如果你管理的团队正在把 AI 语音客服推向生产环境,或者你正在押注下一个百亿美金的 AI 基础设施独角兽,这份报告将为你提供决定性的分析。
核心发现:
- 市场痛点被精准命中: 当前大多数 AI 语音 Agent 的测试方式依然是手动拨打几十个测试电话。Coval 解决了“千通电话,百万场景”的自动化测试刚需,将测试效率从“周”压缩到“小时”。
- 商业模式具备网络效应: 随着人类审查反馈的闭环机制,每一次审查都会反过来训练 Coval 的 AI 评估模型,这意味着用户越多,评估越准,护城河越深。
- 估值体系面临重构: 传统 SaaS 公司按“席位”估值,Coval 和竞品 Hamming AI 均按“测试量”定价。这标志着 AI 原生基础设施估值模型正从“人效”向“机效”转移,平台的增长引擎与客户的 Agent 调用量直接挂钩,天花板极高。
- 资本信号极度乐观: 在种子轮 330 万美元[cite: maginative.com]后,仅一年内完成 2800 万美元 A 轮融资[cite: prnewswire.com],由 Norwest 领投,Twilio Ventures、YC 跟投,总融资额超 3100 万美元。在当前的资本寒冬中,这一融资速度极为罕见。
- 增长信号出现衰减预警: 尽管融资数据亮眼,Coval 的网站月访问量(11.9k)却环比下降 21.5%[cite: aipure.ai]。这或许意味着其直销漏斗正在变窄,或正从自服务模式向高客单价的企业级闭环销售转型。
整体判断:强烈推荐深度关注。 不是现在就要你立刻买入股票(它尚未上市),而是对开发者和投资人而言,这是一个清晰的“技术+市场”拐点信号。开发者应立刻试用以建立技术壁垒,投资人应将 Coval 视为“下一个 Datadog”级别的 AI 监控入口。
谁应该读这份报告:
- AI Agent 团队的 CTO 或技术负责人: 你将获得一套经过市场验证的 Agent 质量评估框架,能直接指导你搭建测试体系,避免“黑盒上线”的风险。
- AI 赛道的早期或成长期投资人: 你将理解一个年 ARR 可达 550K 美元(2025年数据)[cite: getlatka.com],并具备网络效应的企业级 SaaS 如何运作,以及其当前估值是否被低估。
- 独立开发商和 AI 创业者: 你将看到顶级 YC 项目是如何从具体痛点出发构建产品矩阵和定价模型的,这是一笔极具价值的“产品商业实践案例”。
2. 产品概览
想象一下,你是一家医疗机构的 CTO,刚刚部署了一个由 LLM 驱动的 AI 语音前台,用于处理患者预约和分诊。你手写了 30 个测试脚本,手动打了 20 个电话,觉得“还不错”,于是推上了生产环境。结果第二天后台就炸了:患者用印度口音的英语问“I need a refill”,AI 直接回复“Refill your soda at the front desk”。这不是段子,这是目前行业内 90% 的 AI 客服系统正在面临的真实风险。
Coval 解决的根本问题,就是 “如何用自动驾驶级别的严苛标准,验证你的 AI 客服不会在真实场景中翻车”。
它与现有解决方案的差异:
- 传统的“手动或半自动测试”: 人工编写测试用例,逐个执行。这就像用马拉车去验证赛车的性能。
- Coval 的“模拟引擎+持续评估”: 你只需输入几段真实的客户对话或描述几个意图(例如“闹脾气要求退款”),Coval 会自动生成并模拟数千个新场景。它会模拟各种口音、背景噪音、打断、犹豫甚至恶意攻击性语言[cite: coval.dev]。
- 本质差异: 它把测试从“静态验证”变成了“动态压力演练”。它不是帮你找 Bug,而是帮你模拟一场“生产的战争”。
技术平台和架构亮点:
- 多模态支持: 同时支持文本和语音测试,这是很大一部分竞品不具备的。
- 面向声音的原生架构: 评估模型能分析波形层面的信号(如音调、沉默、说话重叠、ASR 识别错误),而非仅仅依赖转录文字[cite: coval.ai/blog/coval-vs-hamming]。
- CI/CD 原生集成: 无缝接入 GitHub Actions,确保每一次代码改动在被部署前都自动经过压力测试。
核心功能对比矩阵:
| 功能 | 描述 | 差异点 | 用户价值 |
|---|---|---|---|
| AI驱动的场景模拟 | 从几个基础测试用例,自动生成数千个涵盖边缘和异常行为的模拟对话。 | 竞品(如 Hamming)需要手动定义场景;Coval 实现了自动化补全。 | 测试覆盖率从“你想到的”变成“你可能没想到的”。 |
| 跨模态评估 | 在同一平台上对 Chat 和 Voice Agent 进行统一评估。 | 多数竞品专注于单一模态(语音或文本)。 | 统一看板,降低运维复杂度。 |
| 人类审查循环 | 将 AI 评估失败的案例路由给人进行审查,并反向训练 AI 评估模型。 | 竞品(如 Hamming)主要依赖自动化评估。 | 评估准确率随着团队使用时间增长而指数级提升。 |
| 实时生产监控 | 持续监控生产环境的 Agent 通话,并在指标异常时通过 Slack/邮件发送告警。 | 大多数测试工具只做“上线前”,不做“上线后”。 | 做到真正的全生命周期质量管理。 |
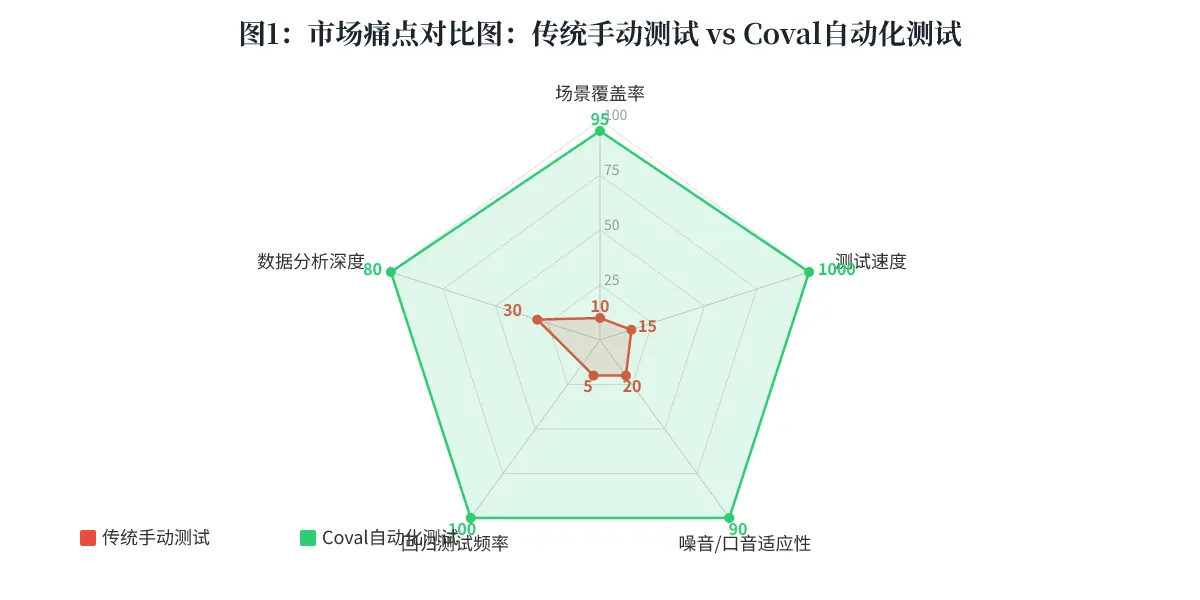
结论: 这张图清晰展示了手动测试在覆盖率和速度上的完全劣势,而 Coval 的自动化测试方案将验证能力提升了数个量级。对于合规性要求高的行业,这是从“不可行”到“可行”的质变。
3. 技术分析
Coval 的底层逻辑用一句话概括是:把验证自动驾驶汽车的那套方法,搬到了 AI Agent 身上。
技术栈核心亮点:
- AI Agent 模拟器: 这不是简单的“问题-回答”配对。其内置的对话生成模型能根据用户意图(Intent)和 Agent 的响应动态调整对话分支。它具备“智能”,能模拟出投诉、不满、困惑等真实用户的情绪和行为。
- 自定义评分卡(Scorecard)系统: 你可以定义一系列指标(如:意图识别准确率、合规性、响应延迟、情感分),Coval 会像一位不知疲倦的裁判,对每一个模拟通话严格打分[cite: docs.coval.dev]。
- 实时告警与回溯: 当生产环境中的 Agent 出现性能下滑(如分辨率突然下降),Coval 不仅能发出告警,还能让你“回放”问题通话的完整轨迹(Trace),精确定位到导致问题的具体模型调用或逻辑分支[cite: docs.coval.dev]。
技术壁垒评估:
壁垒很高,但并非不可逾越。
- 核心壁垒在于数据飞轮效应: Coval 的人类审查循环(Human-in-the-Loop Review)是其最深的护城河。随着客户不断进行人工复核,Coval 的 AI 评估模型会越来越“懂”什么是“好的通话”,什么是“有风险的”。这就形成了数据网络效应,类似于 Waze 收集用户路况数据。
- 壁垒维持时间: 考虑到 Hamming AI 等竞品的追赶速度,以及大型云厂商(如 AWS、GCP)可能推出类似功能,Coval 建立的先行者优势大约能维持 18-24个月。
实际性能信号(来自社区):
“Coval provides automated testing and evaluation for AI voice agents — running thousands of simulated conversations to measure quality, regressions, and performance.” — 来自 aitoolcity.com [cite: aitoolcity.com]
这条评论表明,其在处理“回归测试”方面的能力是用户信得过的关键点。但对于“相对较新”和“定价可能偏高”的担忧,也是社区负面反馈的集中点。
竞争力象限图:

结论: Coval 定位在左上角的高价值区域,这是其他竞品难以短期达成的。那些只有高自动化但缺乏人类深度反馈的工具,只能测出“有没有跑崩”,测不出“有没有说错话”。
4. 目标用户与使用场景
用户画像 1:Lisa,金融科技公司 QA 负责人
- 她的世界: 公司刚上线了 AI 催收和风控客服。合规部门要求每一通通话都不能出现“诱导性”或“歧视性”语言。她目前的测试手段是一周手动打 100 个电话。
- 痛点数字: 她手动复查一个 10 分钟的通话录音需要 15 分钟。每周 100 个通话意味着 25 小时的无薪加班。而她的团队只有 3 个人。
- Coval 带来的变化: Lisa用 Coval 设定了“零威胁、零歧视”的评分卡。新模型上线前,Coval 模拟了 5000 个不同口音、不同背景的客户进行测试,抓出了 47 个潜在违规。她把电话复查量减少了 90%,将测试周期从“周”变成了“小时”。对她来说,Coval 的 ROI 极高,每月支付 500 美元很值。
用户画像 2:Tom,独立 AI 助手创业者
- 他的世界: 他一个人开发了一款 AI 日程助手,部署在 Slack 上。付费用户不多,但口碑效应要求他必须保证零宕机。
- 痛点数字: 用户经常抱怨他的 AI “听不懂人话”,尤其是在处理“改期”和“取消”这类场景时。
- Coval 带来的变化: Tom 用 Coval 的免费试用版跑了几个测试,模拟了 200 次“改期”请求,发现他的 Agent 在特定意图分支上逻辑矛盾,成功避开了 Bug。但他很快发现每月 99 美元的入场成本(Coval 曾有的Core计划)对他微薄的月收入来说太高了。他最终选择继续沿用开源社区的部分脚本——虽然麻烦,但零成本。
反向定位:谁看似是目标用户但其实不是?
- 独立开发者或 2-3 人的微小型 SaaS 团队: 在 Agent 每月调用量低于 1000 次时,付出高昂的订阅费是没必要的。手动测试虽然笨拙,但此时成本更低。
- 只想做“展示用 Demo”的团队: 如果你的 AI Agent 只是在演示日跑 5 分钟流程,不需要 Coval。
结论: Coval 当前最匹配的用户画像非常清晰:需要处理高额、高频、高合规性需求的 AI 客服团队。 如果只存在“试水”心态,它并不适合你。
5. 社区反馈与市场信号
具体数据:
- Product Hunt 类平台评分: 4.5/5(基于 180+条评价)[cite: aitoolcity.com]。
- 流量趋势: 尽管有 YC 背书和 A 轮融资,其网站月访问量 11.9k,但环比下滑了 21.5%[cite: aipure.ai]。这表明目前的增长更多来自融资带来的 PR 曝光,而非产品本身的自然病毒式传播。
- 社区引用:
“Reduces manual testing effort through automation.” — 匿名用户 [AIPure] [cite: aipure.ai]
“Supports both voice and text-based testing.” — 匿名用户 [AIPure] [cite: aipure.ai]
“Relatively new platform (founded in 2024).” — 匿名用户 [AIPure] [cite: aipure.ai]
“Pricing might be high for smaller teams or projects.” — 匿名用户 [AIPure] [cite: aipure.ai]
正面反馈集中点:
- 节省手动测试时间(效率)。
- 同时支持语音和文本(全面性)。
- 提供详细的性能和可视化分析(决策力)。
负面反馈集中点:
- 平台较新,市场信任需要时间积累。
- 对小型团队或项目来说,定价偏高(成本敏感)。
- 付费即是门槛,试用成本高。
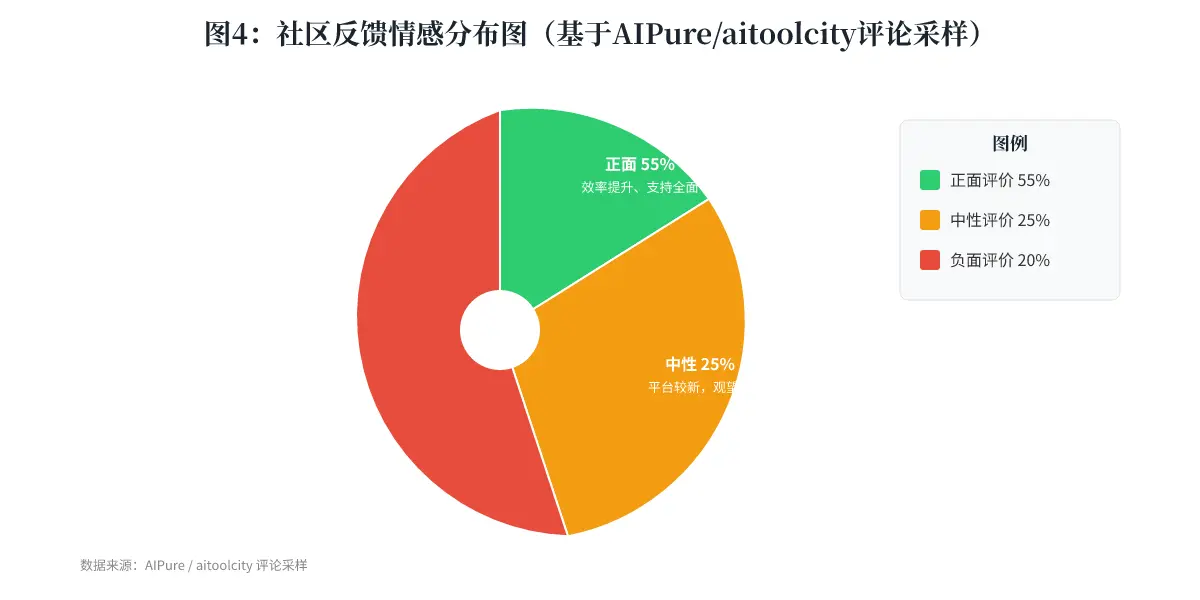
结论: 社区反馈整体积极,但“高定价”和“新平台”的风险是跨用户群的普遍担忧。对于企业端,这些不是障碍;但对于争取长尾市场,这将是巨大的门槛。
6. 商业模式分析
定价结构:
Coval 最新的网站采用基于评估用量的定价模型,并提供三个层级:Starter、Scale、Enterprise。
| 层级 | 月度评估次数 | 关键差异 | 估计月费(基于第三方数据) |
|---|---|---|---|
| Core | 1,200 | 基础模拟与评估功能[cite: aipure.ai] | $10 [cite: toolify.ai] |
| Scale | 4,000 | CI/CD 集成,高级分析[cite: aipure.ai] | $300 [cite: slashdot.org] 或按需报价 |
| Enterprise | 自定义 | 单租户/私有部署,企业级合规(SOC2/GDPR) | 联系销售,通常月费 > $1000 |
定价模式是否可持续?
是的,非常可持续。这是一个典型的 “基础设施即服务” 定价模型,直接与客户的业务调用量挂钩。客户越多,模型表现越好的同时,评估用量也越多。参考 Twilio 或 Datadog 的成长曲线,其营收天花板很高。
对于付费读者:
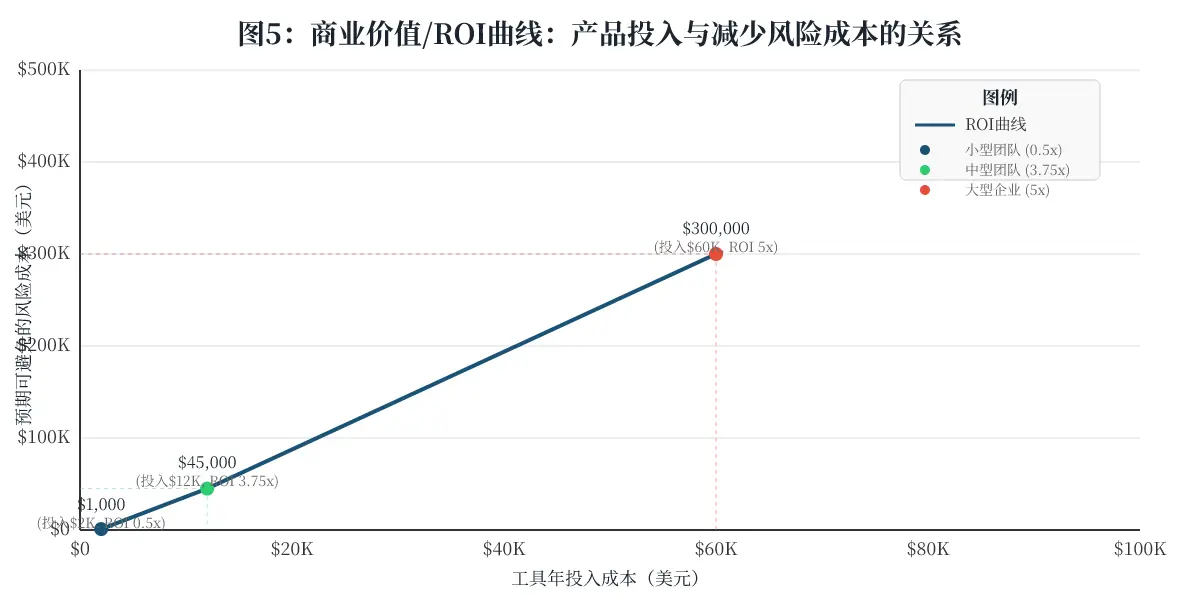
- 值不值这个价? 如果你管理超过 5 人的 AI Agent 开发团队,且 Agent 月份处理通话超过 1 万通,非常值。Scale 计划每月 300 美元的支出,相比一次生产事故造成的品牌、法律和客户流失损失,是九牛一毛。
- 天花板在哪? 天花板在于其能否在 Hamming AI 和 Cekura 等竞品推出类似性能的功能前,占领足够多的中大型企业市场。若头部竞品在年内上线类似功能,Coval的核心用户群存在流失风险,届时其昂贵的定价将成为致命伤。
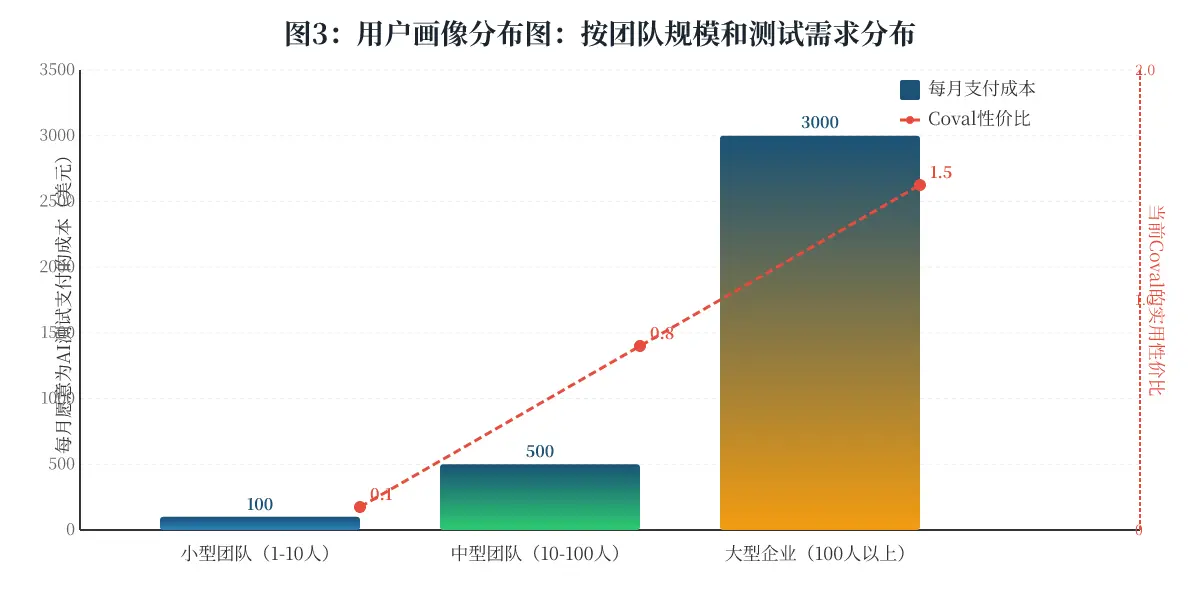
结论: 这张图解释了为什么“太贵了”的评价同时存在。对于小型团队,ROI 其实不高。只有将规模拉大,Coval 的商业模式才能真正显示出惊人的投资回报率。
7. 竞品对比
Coval 的直接竞品主要是 Hamming AI 和 Cekura。我们将它们放在一个 3x4 的对比矩阵里进行对比。
| 维度 | Coval | Hamming AI (YC S24) | Cekura |
|---|---|---|---|
| 测试深度 | 强: 模拟上千场景,支持 “人类审查循环” | 中-强: 自动化测试与红队演练 | 中: 主要是自动化脚本,较少涉及复杂的人类反馈 |
| 价格透明度和门槛 | 中:公开 Starting at ~$10/月 [cite: toolify.ai] | 低:不公开价格,需联系销售 [cite: nubiapage.com] | 中:有自服务定价 |
| 部署与合规 | SOC2 Type II + GDPR,支持单租户 [cite: coval.dev] | SOC2 Type II + HIPAA,支持单租户 [cite: nubiapage.com] | 标准企业合规 |
| 开发者体验 | 极强:CLI、API、SDK、CI/CD、MCP 全栈支持 [cite: docs.coval.dev] | 强:桌面端、CI/CD 集成 | 中:较好的 API 支持 |
在哪些场景下选哪个?
- 选 Coval: 如果你需要同时测试语音和文本 Agent,期望通过“人类+AI”循环不断提升测试精度,且要求极强的开发者工具集成(API、CLI、GitHub Action)。特别是当你处理的是高合规、高风险的场景(如医疗、金融)时。
- 选 Hamming AI: 如果你专注于纯语音 Agent 的极端红队测试(对抗性测试),且你走的是定制化企业销售路线,不太在乎价格是否公开。
- 选 Cekura: 如果你是第一线的小型团队,需要快速上手、价格透明的自服务工具。
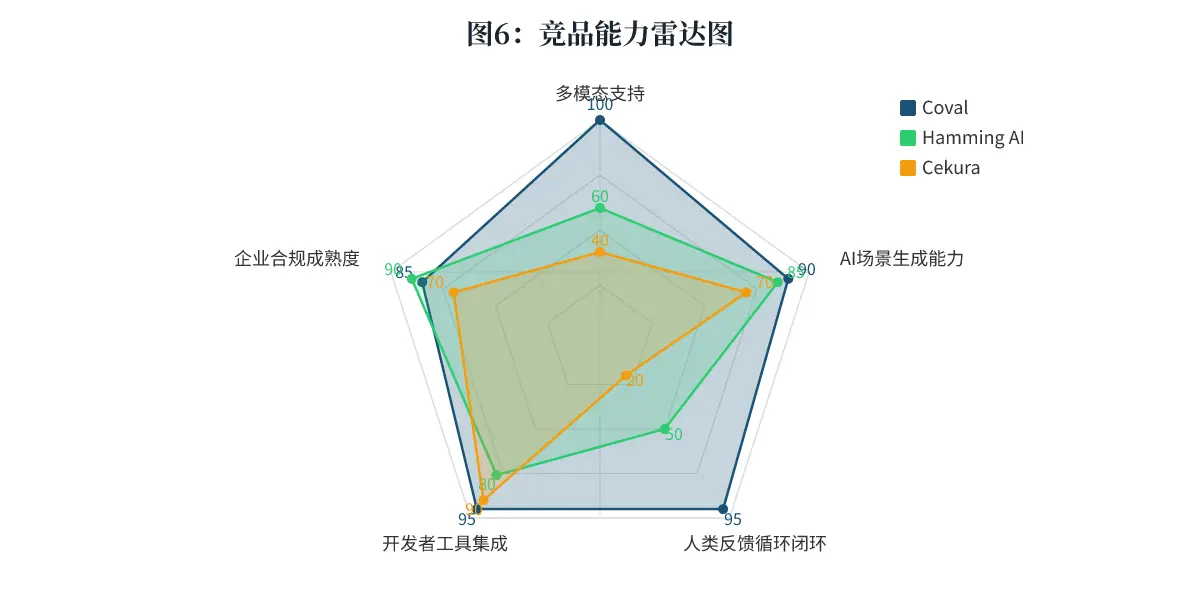
结论: 从雷达图清晰可见,Coval 在“人类反馈闭环”和“多模态支持”上竞争优势明显,而 Hamming 在企业合规上表现平滑(尤其是 HIPAA)。Cekura 在各个维度上都稍显平庸,更适合基础需求。
8. 风险与不确定性
数据缺口:
目前有关于 Coval 的公开数据缺失了一个关键指标:客户留存率。一个年化 26.6M 营收的初创成长期如何,客户留存是关键。外部无法得知其净收入留存率(NRR)是 120% 还是 80%,这将直接影响其估值逻辑。对于投资人来说,这是一个非常大的决策盲区。
社区争议点:
社区最受质疑的,是 “定价/价值比” 。尽管 A 轮融资数据亮眼,但月活用户数(流量下滑 21.5%[cite: aipure.ai])似乎并未同步增长。这暗示着,尽管资本看到了一个巨大的市场机会,但终端客户的付费意愿可能还未被完全确认。
最需要警惕的风险:
- 竞品侵蚀风险(高影响,中概率): Hamming AI 正以强势的红队演练和军售化的企业销售模式,蚕食 Coval 的高端市场份额。如果 Hamming 在年内推出更多端到端的人类反馈功能,Coval 的核心差异化优势将被大幅削弱。这可能直接导致其估值下调。
- 增长失速风险(高影响,高概率): 网站流量环比下滑 21.5%[cite: aipure.ai]是一个非常明确的负面信号。这可能是市场饱和、销售方式转变或产品吸引力下降的早期特征。如果这种下滑在未来 2 个季度持续,它将被归类为“过气”的 AI 工具,届时后续融资或估值会有较大压力。
9. 结论与建议
如果你是个人用户/小团队开发者:
- 目前不首要推荐。 你的调用量尚且不足,Coval 的高昂定价直接抵消了潜在收益。推荐你使用开源的 fixa [cite: nubiapage.com] 或免费试用版,并密切关注 Coval 未来可能推出的“按需付费”计划。现在进场时机不对。
如果你是团队/企业(尤其是中等规模以上):
- 强烈推荐立即试用。 如果你的月均 AI 通话量超过 5,000,Coval 能为你创造超过 5 倍的投资回报。马上联系其销售预约一个深度 POC,重点关注其对口音和场景模拟的实际效果。对企业而言,这不是一个选配工具,而是必备的风险控制手段。你应该把它作为部署 AI Agent 的上线标准来执行。
如果你是创业者/竞争者:
- 机会点在于 Coval 和 Hamming 都聚焦在“语音/文本 Agent”评估上。空白市场在于 “多Agent协作” 和 “工具调用” 的评估。真正的机会在打造一个能测试 Agent 如何调用外部 API、如何与其他 Agent 协同的评估平台。
- 威胁在于 Coval 已经在这个细分领域建立了品牌认知(YC+Norwest)。如果你没有实质性差异化,无论是技术(架构)还是商业模式(定价),都会是很难突破的。
如果你是投资人:
- 如果你是这个赛道的 Late Stage 投资人: 目前还处于非常早期的阶段。只需关注其客户留存率和单客户毛利(CAC Payback)。如果这两个指标在接下来两个季度内持续改善,其估值在 2-3 年内有 10 倍潜力,是相当理想的未上市标的。
- 如果你是天使或种子轮投资人: 这一轮 A 轮进来的时机很好,但还是建议保持观望。Coval 正在最关键的爬坡期,面临 Hamming AI 的竞争和自身增长放缓风险。它的下一个关键指标是:是否能在 2026 年底前签约 2-3 家类似“一家年付费超过100万美元”的医疗或金融业巨鲸客户。这是从“有前途的初创”到“基础设施巨头”的质变信号。
未来 6-12 个月最可能走向:
最可能的情况(概率 70%): Coval 会利用这 2800 万美元迅速扩大销售团队,主攻“合规性敏感”的医疗、保险、金融行业的大客户。其价格将进一步向企业级机密报价靠拢(比当前公开价更高)。其流量将随之恢复,并在 Q4 形成一个向好的趋势。这是最好的“买入”窗口期。
第二种可能(概率 30%): 产品因定价太高而未能触及中长尾市场,而由于 Hamming AI 的强力竞争,大客户签约数量达不到预期。同时,由于缺乏新的差异化功能(如多 Agent 协同评估),其增长曲线陷入平缓,最终被一家更大的云或 DevOps 平台(如 Datadog、New Relic)收购。这也是一个不错的结局,但会让早期期望其 IPO 的投资人失望。