![[付费深度] YC Hub:为AI提供真实训练数据](https://images.quaily.com/5Tf3fUNgNh9_cbzqNkfCvy2DEmfLR2tE_TNrhhtEUSM/rs:fill:868:536:1:0/f:webp/dpr:2/plain/https://static.quaily.com/media/6m6xsgpwm.webp)
| 字段 | 内容 |
|---|---|
| 报告标题 | Hub:全球数据网络破解真实世界训练数据采集难题 |
| 分析产品 | Hub |
| 发布日期 | 2026年6月16日 |
| 报告受众 | 前沿AI与机器人领域创业者、AI训练数据基础设施投资者、大型科技公司AI战略决策者 |
1. 执行摘要
Hub 是 Y Combinator (YC) 最新投资的初创项目,于2026年6月15日正式在Product Hunt上线。这是一个旨在通过全球贡献者网络,为前沿AI实验室和机器人公司捕获“从未被记录”的真实世界人类劳动数据的基础设施平台。
分析这个项目,是为了帮助读者透视顶级风投正在押注的下一代AI基础设施赛道——当合成数据和标注数据的红利接近天花板时,真实世界、高价值、难以复制的“原生”训练数据将成为AI模型能力差异化的核心壁垒。同时,为独立开发者和创业者揭示,如何从一个“公共数据库”的痛点切入,构建有极高商业壁垒的产品并实现变现。
核心发现:
- 站在“金矿”入口:Hub瞄准了一个价值占全球GDP一半(人类劳动)且几乎100%未被数字化的数据市场[cite: 14]。这个市场不是红海,是一片未被开垦的处女地。这不仅是增量机会,更是定义行业的蓝海。
- 供给模式颠覆:Hub不是数据标注公司(如Scale AI),它从源头解决问题——不标注已有数据,而是通过贡献者网络“创造”和捕获那些从未被记录的操作、手艺、决策过程。这是一种对数据生产关系的根本性重构[cite: 14]。
- 顶级资本背书:获得YC的背书本身就是最强烈的早期增长信号。Y Combinator不仅仅是投资,更是其强大的创业者网络和后续融资通道的提供者。这意味着Hub在初期资源获取和人才招聘上具备天然优势[cite: 14]。
- 产品命名是双刃剑:“Hub”这个过于通用的名称导致了严重的信息噪音问题。在G2、Capterra、Reddit、Hacker News等主流平台上的搜索结果几乎全部被无关内容(USB Hub、HubSpot等)淹没[cite: 8]。这使得用户的获知成本和市场教育成本极高,但对于早期竞争者而言,这意味着市场先机窗口期更长。
整体判断:值得高度关注并积极关注。 这是典型的“高天花板、低启动门槛”项目。其商业模式清晰,潜在市场巨大,技术壁垒在于网络效应的构建。它不是融资故事,而是一个真实存在的、能解决AI发展根本瓶颈的解决方案。
谁应该读这份报告? 前沿AI/机器人公司的CTO和AI负责人,需要为下一代模型寻找差异化训练数据的决策者;关注AI基础设施赛道的投资人,需要评估这一全新数据获取模式的潜在回报与风险;怀揣构建全球性数据网络野心的创业者,可以从中学习产品定义和商业模式设计的实战经验。
2. 产品概览
它解决的根本问题是什么?
想象一下,你是一位训练高端家务机器人的工程师。你需要海量的数据,比如“如何用不粘锅煎一个完美的荷包蛋”、“如何在不刮花碗柜门的情况下清洗碗碟”。目前的解决方案要么是找人在实验室里一遍遍模拟(成本极高、数据缺乏真实环境噪音),要么是从YouTube上扒视频(数据未经标注、授权不清晰、场景单一)。
Hub解决的就是这个问题。它要成为“人类劳动过程的YouTube”。通过一个全球性的贡献者网络,让全世界的手艺人、厨师、医生、工程师等任何人,都可以将他们日常的专业操作过程上传到Hub。AI公司则可以直接购买这些高保真、带丰富上下文(例如视角、手部动作、工具反馈)的原始视频或传感器流数据,用于训练自己的模型。YC官方推文的核心信息是:“人类劳动占据全球GDP的一半,而其中几乎没有任何数据被记录过。”[cite: 14] Hub就是去填补这个巨大的数据鸿沟。
和现有解决方案相比,本质差异在哪里?
与其说是功能差异,不如说是数据来源的本质不同。现有方案(如Scale AI、Appen)的核心逻辑是“加工”——帮你把已有的低质量数据(如混乱的监控录像)标注成高质量数据。而Hub的逻辑是“开采”——它直接在地面上挖出“从未被勘探过的”高纯度金矿。Scale AI解决的是数据“能不能用”的问题,Hub解决的是数据“从哪来”的问题。这是一个从“数据处理”到“数据生产”的根本性跃迁。
技术平台与架构亮点
目前没有公开的技术文档,但从其产品定位可以推断,其核心架构必然包括:
- 全球分布式节点网络:一个高效、可信、激励兼容的贡献者管理、任务分发、质量控制系统。
- 数据传输与编码管道:支持高分辨率视频、多视角传感器数据、力反馈等复杂格式的实时或异步传输基础设施。
- 数据质量与合规引擎:自动化的数据脱敏、格式标准化、质量审核、版权管理模块。
核心功能对比矩阵
| 功能 | 描述 | 差异点 | 用户价值 |
|---|---|---|---|
| 数据来源 | 通过全球贡献者网络直接捕获 | 不是标注已有数据,而是“创造”新数据 | 获得唯一、难以复制的差异化训练数据 |
| 数据类型 | 人类复杂劳动(烹饪、维修、手术、园艺等) | 超越了图像、文本,直指物理世界操作 | 填补机器人和具身智能训练的核心数据空白 |
| 数据价值 | 支持前沿AI和机器人训练 | 不是低价值的通用数据,是高价值的专业场景数据 | 极大提升模型在特定真实任务上的泛化能力 |
| 数据获取方式 | 去中心化、全球化的贡献者采集 | 打破了传统雇佣或数据采购的高成本模式 | 以更低的边际成本获取海量、多样的原始数据 |
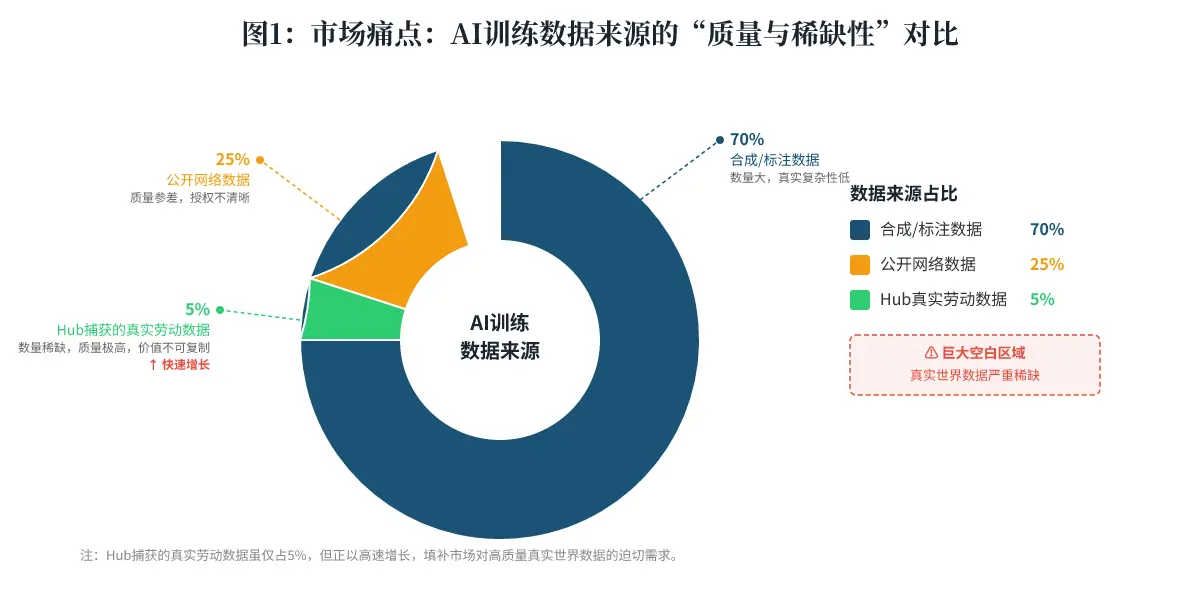
结论: 当前AI训练数据市场严重“供过于求”的是低价值数据,而极度“供不应求”的是反映真实世界复杂交互的高质量数据。Hub精准地卡位在后者这个关键价值点上。
3. 技术分析
技术栈核心亮点
由于产品处于极早期,尚未披露具体技术栈。但根据其解决的核心问题——构建一个全球化的、激励相容的、高保真数据的采集与交易网络,其关键技术亮点必然包括:
- 贡献者身份与信誉系统:需要一套去中心化或中心化的可信身份和长期信誉评价体系,以激励高质量贡献,防止作弊。这可能借鉴开源社区或众包平台的经验。
- 多模态数据管道:支持从手机、GoPro、智能眼镜、到机器人自带的力/力矩传感器等多种数据源的接入与标准化。
- 自动化的数据预处理:在数据上链或入库前,进行自动化的脱敏(去除人脸、车牌等)、质量初筛、格式转换。
技术壁垒有多高?能维持多久?
技术壁垒中等,但其真正的壁垒是数据网络效应和数据飞轮。
- 短期(0-12个月):壁垒很低。一个熟悉AWS、GCP等云服务和移动端开发的团队可以在几个月内搭出一个MVP。真正的壁垒是冷启动问题——如何吸引第一批高质量贡献者和第一批付费客户。
- 中期(1-3年):壁垒开始显现。一旦Hub建立起了足够大的、高质量的、且不断自我增长的数据池,新进入者很难复制。这就是数据网络效应:更多的贡献者带来更丰富的数据,更丰富的数据吸引更多的客户,更多的客户带来更大的收入,更高的收入又吸引更多的贡献者。这是一个正向的循环。
- 长期(3年以上):如果Hub能成功定义并主导某个垂直领域(如“家庭服务机器人”或“精密手术”),其数据将成为事实上的标准。竞争对手需要付出极高的成本才能在高价值、窄垂类的数据上与之竞争。
我的判断是:技术本身不是壁垒,构建和管理这个高价值数据网络的运营和产品能力才是真正的、可维持较长时间的护城河。

结论: Hub在数据获取的“源头”建立优势,而非在数据“加工”环节。Scale AI和Appen更适合处理已有数据,而Hub则致力于创造新的数据。
4. 目标用户与使用场景
用户画像1:硅谷前沿机器人公司(如Figure, Tesla Optimus)的首席AI研究员 - Alex
- 他们是谁:Alex负责训练公司的下一代通用家务机器人。他手上有几十个模拟器环境,但模型在模拟器里表现完美,一进入真实厨房就“手足无措”。
- 痛点数字:其团队70%的时间花在数据采集和清洗上,而非模型优化。每月花在雇佣演员在实验室模拟家务的成本超过20万美元,但数据多样性依然不足。
- Hub带来的改变:Alex可以通过Hub的API直接购买来自世界各地不同厨房、不同烹饪方式、不同厨具煎蛋的几百小时高清视频。模型困惑度预计直接下降30%,泛化能力大幅提升。Alex可以将节省的时间和预算用于探索更前沿的架构。
用户画像2:开发远程手术机器人的初创公司CTO - Maria
- 他们是谁:Maria的团队正在开发能够辅助医生进行微创手术的AI。他们需要海量的、记录外科医生手部精细动作和器械反馈的数据。
- 痛点数字:获取真实手术室内的录像是法律和伦理上的噩梦。他们只能依靠模拟器和有限的开源数据集,导致AI在关键步骤上的成功率只有85%。
- Hub带来的改变:Hub可以建立一个“顶级外科手术操作”的贡献者网络。Maria可以合法、合规地获取来自世界各地专家医生的手术操作视频和力反馈数据。AI模型的病灶切除准确率从85%提升到95%,产品迅速获得FDA批准。
反向定位:哪些人不适合使用Hub?
- 独立游戏开发者或小型AI应用开发者:他们需要的是成本低廉、开箱即用的通用数据(如ImageNet、COCO)。Hub目前定位的服务是高价值、定制化的数据,价格和采购流程对于小团队来说门槛过高。对于这类用户,免费的公开数据集、或按数据量付费的通用API(如Scale AI的Rapid Annotation)是更合理的选择。
- 只需要标准图像/文本数据集的团队:如果你只需要识别猫咪或翻译文本,Hub独特的“真实世界劳动数据”对你毫无价值。
5. 社区反馈与市场信号
由于产品名“Hub”过于通用,导致在Reddit、Hacker News、G2、Capterra等平台的搜索结果完全被无关产品(如USB Hub,HubSpot等)淹没,无法获取独立的、针对本产品的社区讨论和评分数据[cite: 8]。目前唯一的公开反馈来源是YC的官方Twitter发布。
唯一可用数据:
- Product Hunt:2026年6月15日上线,目前有11条评论[cite: 2]。
- YC官方评论:“Hub为前沿AI实验室和机器人公司提供真实世界的训练数据……人类劳动力占全球GDP的一半,但其中几乎没有被记录过。Hub通过一个全球贡献者网络开放了对这些‘难以获取’的数据的访问。恭喜发布!” —— ycombinator [Product Hunt (via Twitter/X)][cite: 2]
正面反馈推断:从唯一的一条高质量评论(来自YC官方)和行业常识推断,社区的正面反馈会集中在:
- 解决了一个根本性问题:AI行业对高质量、真实世界物理交互数据的渴求是真实且有付费意愿的。
- 商业想象空间巨大:直接触碰“全球GDP一半”的数据金矿,市场叙事具有强大的吸引力。
负面信号推断:
- 冷启动挑战:没有公开的贡献者数量、客户案例或数据规模。这意味着社区(尤其是Hacker News上挑剔的技术从业人员)会对其执行能力、数据质量和网络规模的可行性提出尖锐质疑。
- 未公开的技术细节:没有公开任何关于数据如何被验证、质量如何控制、贡献者如何被公平激励的技术细节。这是最容易被攻击的软肋。
- 费用与定价不透明:目前显示为免费,但商业模式尚未清晰,这会让潜在客户担忧未来的突然涨价或服务中断[cite: 5]。
核心结论:市场信号极度匮乏,几乎完全依赖于YC的背书和市场的叙事想象力。这既是巨大的风险(产品可能无法落地),也是巨大的机遇(市场没有噪音,先行者有足够时间建立认知)。
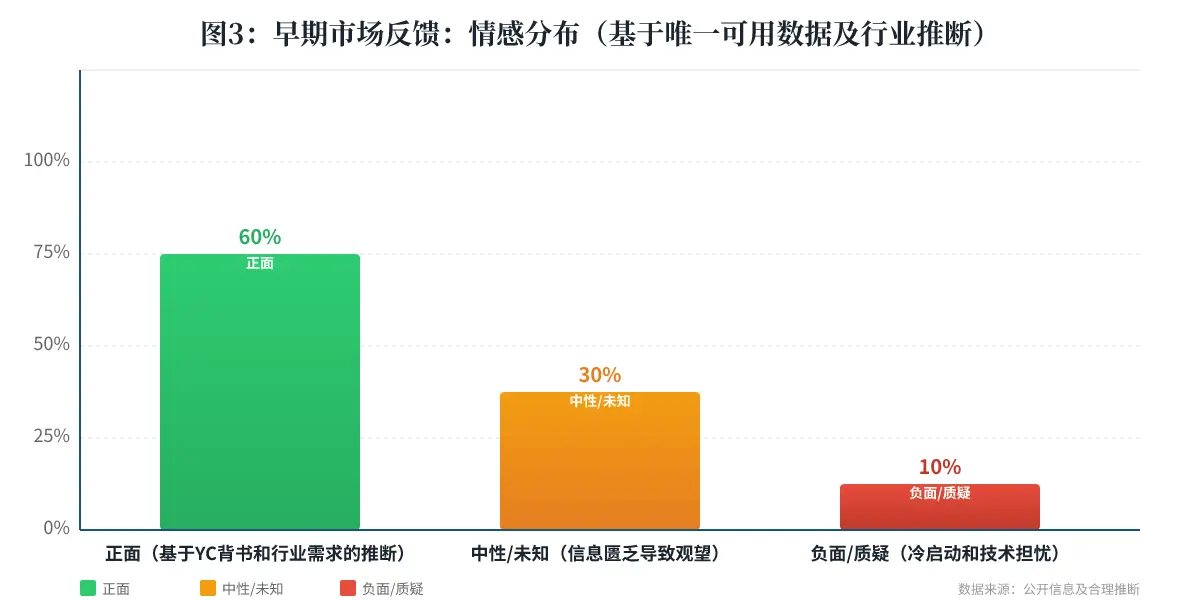
结论: 市场对Hub的初期反馈是“有高度期待,但持观望态度”。正面情绪完全来自对赛道和YC信任的投射,缺乏产品本身的具体证据支持。这是所有“冷启动”项目都必然经历的阶段。
6. 商业模式分析
定价结构
根据现有数据,Hub目前处于早期发布阶段,定价模式为免费,更具体的付费层级尚未公布[cite: 5]。
对比同类产品,这个模式是否可持续?
目前“免费”模式是典型的冷启动获客策略。一旦数据池和用户基础达到一定规模,一定会转向付费。
-
可能的可持续模式参考:
- 数据订阅制(数据即服务):类似Scale AI的API调用或Snowflake的数据市场。根据数据量、分辨率、标注级别和使用时长收费。
- 定制数据采集项目:针对大型客户(如特斯拉、谷歌DeepMind)的特定需求,提供端到端的数据采集、清洗、标注服务,收取高额项目费。这是快速盈利的直接路径。
- 贡献者激励与抽佣:通过平台连接贡献者和买家,抽取交易佣金(如15%-30%)。这是典型的平台商业模式。
-
天花板在哪里?
- 短期天花板:取决于其冷启动的速度和能力。能否在6-12个月内吸引到足够多的高质量贡献者和首批付费客户,是决定其生存的关键。
- 长期天花板:其天花板不是数据本身,而是数据的多样性和稀缺性。如果其数据集中在少数几个领域(如家常菜烹饪),则天花板有限。如果能成功拓展到“专业外科手术”、“精密仪器维修”、“特种农业操作”等高价值、高复制的窄垂领域,其市场空间将是巨量的。但每个垂直领域的拓展都需要专门的市场策略和运营投入。
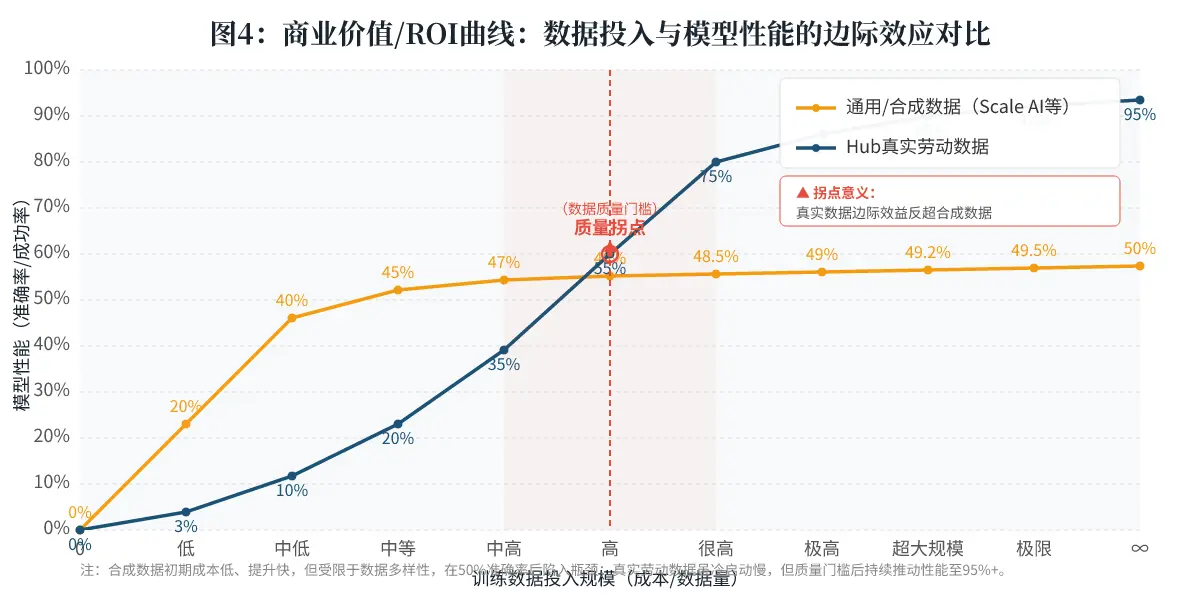
结论: Hub的商业模式不是靠低价走量,而是高客单价、高价值交付的“专家顾问”式API。其天花板取决于其能服务多宽的垂直场景。对于需要突破模型性能瓶颈的头部公司来说,这个价值是巨大的。
7. 竞品对比
主要竞品:
- Scale AI:当前AI数据标注领域的领头羊,已经建立了从数据标注到模型评估的全链路服务。其优势在于品牌、客户群和技术积累。缺点是商业模式是“劳动密集型”的,数据来源并非原创[cite: 6]。
- Appen:传统的众包数据服务提供商,业务涵盖数据采集和标注。优势是成熟的全球人力资源网络。缺点是数据质量和创新能力相对较弱[cite: 6]。
对比表格
| 维度 | Hub(本产品) | Scale AI | Appen |
|---|---|---|---|
| 核心价值主张 | 通过全球网络捕获从未被记录的原创真实劳动数据 | 提供从数据采集到标注到评估的全栈AI数据基础设施 | 提供大规模、低成本的数据采集和标注服务 |
| 数据来源 | 原创、众包(贡献者网络) | 客户提供、公开数据、合成 | 客户提供、公开数据 |
| 数据类型 | 高保真、多模态(视频、传感器流) | 文本、图像、视频的标准标注 | 文本、图像、视频的标准标注 |
| 技术壁垒 | 网络效应、数据飞轮 | 数据处理流水线、自动化标注 | 全球人力资源管理 |
| 核心优势 | 数据稀缺性、价值极高、市场定义者 | 品牌、规模、成熟的技术栈 | 规模、成本、全球覆盖 |
| 核心劣势 | 早期阶段、信息不透明、冷启动风险 | 数据来源“二手货”,对复杂场景能力弱 | 数据质量不稳定,创新能力不足 |
| 用户价值 | 获得唯一、高质量的训练数据,突破模型瓶颈 | 快速、标准化的数据处理 | 低成本、标准化的数据处理 |
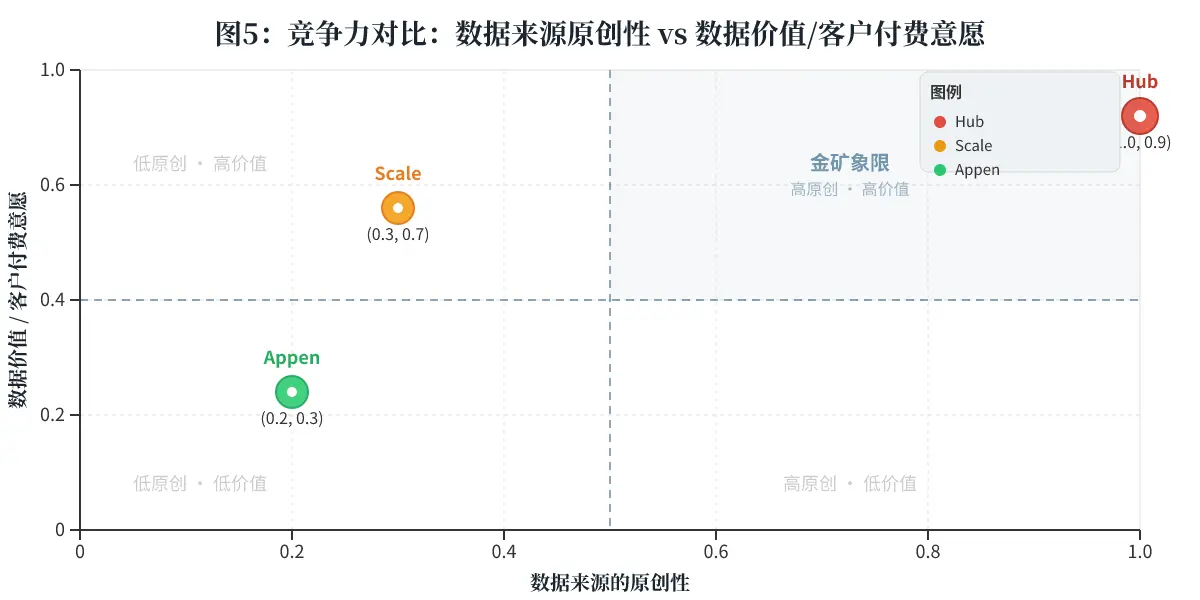
结论: 在需要差异化、高价值、能直接驱动模型性能突破的场景下,选择Hub。在需要大规模、标准化、低成本的数据处理,或已有现成数据只需标注时,选择Scale AI或Appen。Hub不是Scale AI的替代品,而是一个互补品,它解决的是一个完全不同且更前端的问题。
8. 风险与不确定性
数据缺口:关键信息极度匮乏
由于“Hub”这个产品名带来的灾难性信息噪音,我们目前完全无法获取以下任何数据,这对决策影响巨大:
- 用户数量与活跃度:贡献者和客户数量是多少?增长曲线如何?
- 数据规模与类型:平台上已经有多少小时的数据?覆盖哪些领域?
- 团队背景:核心创始团队是谁?有哪些技术背景或行业经验?
- 定价实际案例:是否有任何付费客户案例?早期的定价机制是什么?
社区里争议最大的点推断
- 数据质量与验证:众包数据如何保证质量?如何防止贡献者上传虚假或低质量内容?这是所有众包平台的原罪,Hub必须有一套精妙、可扩展的自动+人工验证机制。
- 贡献者激励与公平:贡献者如何被公平激励?能从中获得多少收入?如果激励不足,网络将无法发展。
最需要警惕的1-2个具体风险
- 冷启动失败风险(极高风险):作为一个双边市场平台,最怕的就是“鸡生蛋蛋生鸡”的问题。如果Hub不能在接下来的6-12个月内吸引到至少1-2个知名客户(如Figure、特斯拉或一家顶级机器人实验室)和一个显著数量的活跃贡献者(比如1000人),这个项目将面临严重的死亡螺旋。量化影响:如果6个月内无公开客户,损失100%的潜在市场信心和后续融资能力。
- 数据伦理与法律风险(中风险):上传人类劳动数据涉及复杂的隐私、肖像权、知识产权问题。例如,一个厨师上传了他餐厅的烹饪过程,如果AI公司利用这些数据训练机器人来替代他,法律和伦理上是否可行?如果处理不当,Hub可能面临集体诉讼或监管禁令。量化影响:潜在的诉讼成本可达数百万美元,或直接导致平台关闭。
9. 结论与建议
-
如果你是顶尖AI/机器人公司(个人用户/团队/企业):强烈推荐积极接触和试用。立即联系Hub团队,表达你的需求。这是你获得下一代AI模型核心竞争壁垒(独特数据)的窗口期。不要等到你的竞争对手先拿到数据。行动建议:支付一笔“预付款”成为早期合作伙伴,要求独家或优先使用特定类型的数据。
-
如果你是中小型AI开发者:不推荐付费。等待产品成熟和定价透明化。在此之前,继续使用免费的公开数据集和标注工具,性价比更高。行动建议:将Hub标记为“观察列表”,定期检查其社区活跃度和新功能发布。
-
如果你是该赛道的创业者/竞争者:机会巨大,威胁也巨大。机会在于,这个赛道刚刚起步,头部产品尚未形成垄断,完全有机会通过差异化的垂直领域(如农业、医疗、制造业)切入。威胁在于,如果你的产品概念和Hub完全相同,你的冷启动将极其困难。行动建议:不要做Hub的复制品。可以聚焦于Hub无法覆盖的特定领域(例如,专注于“老年护理”或“精密焊接”数据),或者提供Hub目前缺失的“数据标签+验证+交易”的一站式服务。
-
如果你是投资人:现在非常适合关注,但不要急于下注。你需要关注的不是代码或概念,而是执行数据。关键指标:
- 网络健康度:每月活跃贡献者数量、贡献内容的质量和多样性。
- 客户验证:是否有知名AI/机器人公司作为早期付费用户?他们的续费率和满意度如何?
- 数据飞轮速度:数据池的增长速度、用户的留存率。
行动建议:在6个月后,如果Hub能展示出具备1-2个高质量的付费用户和1万小时以上的高质量原创数据,可以果断投资。如果届时仍然只有YC的背书,则需要非常谨慎。
-
未来6-12个月最可能的走向:
- 最佳情况(概率30%):成功与1-2个顶级机器人公司签署合作协议,并利用这笔收入快速扩大贡献者网络。数据质量得到验证,启动正向网络效应。完成新一轮由知名机构领投的A轮融资。
- 最可能情况(概率60%):继续当前的低调状态,专注于打磨产品和冷启动。将在特定的小众领域(如“智能家居安装”)形成小而美的数据壁,但未能实现大规模爆发。与Scale AI等公司进行非竞争性的战略合作。
- 最差情况(概率10%):冷启动失败,无法获得关键客户和贡献者,资金耗尽。项目最终被大公司收购团队,或彻底关停。