如果答案是“不知道”,那这篇论文你得看看了。
2026年5月,伊利诺伊大学香槟分校、Meta 和斯坦福大学的研究团队发布了一篇综述论文,提出了一个颠覆性的观点:代码不再只是 AI 的输出产物,而是 AI Agent 的运行基础设施。
说白了,以前我们让 AI 写代码,现在代码变成了 AI 的“操作系统”。

问题出在哪?
现在的 AI Agent 有个致命问题:你不知道它在想什么,也不知道它做了什么。
想象一下,你雇了个员工,他每天在办公室忙活,但你看不到他的工作记录,不知道他的决策逻辑,也无法验证他做的事是对是错。你敢让他管公司的核心业务吗?
这就是当前 AI Agent 的现状。大部分 Agent 系统就像个黑盒:
-
推理过程是一堆文本,你看不懂它的逻辑
-
执行动作后没有可验证的记录
-
状态转换完全不透明
-
多个 Agent 协作时,谁做了什么根本理不清

ent 推理全靠自然语言,你只能看到它“想”了什么,但不知道它“算”对没有。
现在把推理过程写成代码:
-
中间计算可以执行验证
-
推理步骤变成可检查的程序
-
错误可以被捕获和修正
举个例子:以前 Agent 算数学题,它说“答案是42”,你只能信。现在它生成一段 Python 代码,你运行一下就知道对不对。
更进一步,像 DeepSeek-Prover-V2、Lean4Agent 这些系统,直接用形式化证明语言(Lean、Coq)来做推理,每一步都能被数学验证器检查。这就像给 Agent 配了个“审计员”,它想糊弄你都不行。
2. 行动变得可追溯
Agent 要操作外部环境——控制机器人、点击网页、修改代码库——这些行动必须可追溯。
代码作为行动接口的好处:
-
每个动作都是可执行的程序
-
可以回放、可以测试、可以回滚
-
失败了能看到具体哪一步出错
真实场景:SayCan 让机器人执行任务时,不是直接发指令,而是生成可执行的 Python 策略代码。如果机器人抓取失败,你能看到代码里哪个条件判断出了问题,而不是只知道“它失败了”。
Voyager 更进一步,它在 Minecraft 里自己写技能库,每个技能都是一段可重用的代码。它学会了“挖矿”这个技能,下次遇到类似任务直接调用,不用重新学。
3. 环境变得可建模
Agent 需要理解它所处的环境,但环境状态往往是隐式的、模糊的。
用代码建模环境的好处:
-
状态转换有明确的程序表示
-
可以用测试验证环境行为
-
多个 Agent 可以共享同一个环境模型
实际应用:SWE-bench 用单元测试作为“环境真相”。Agent 要修复一个 bug,不是说“我觉得修好了”,而是跑测试,测试通过才算完成。这就把主观判断变成了客观验证。
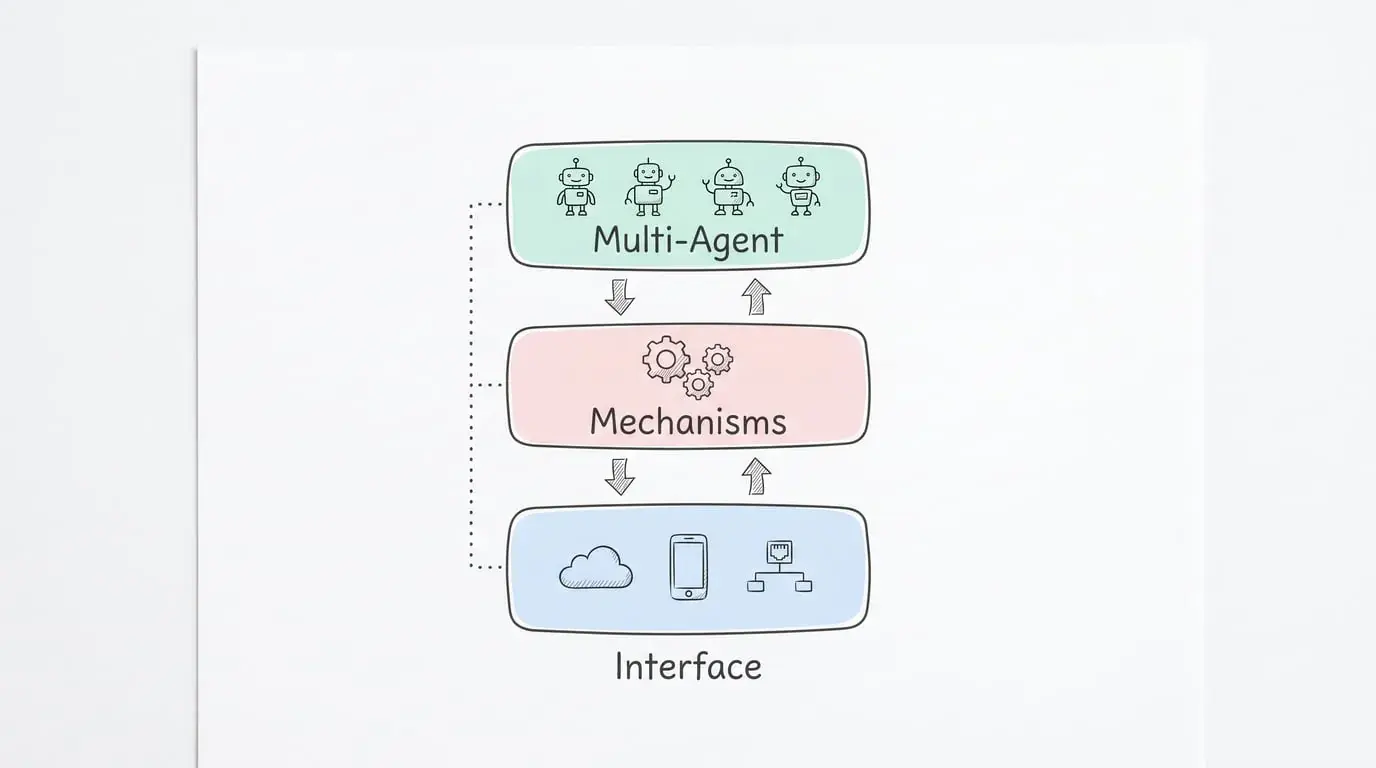
这套框架怎么运作?
论文提出了一个三层架构,我觉得这是最有价值的部分:
第一层:接口层
代码怎么连接 Agent 的三大能力:
-
代码用于推理:把思考过程变成可执行程序(PoT、PAL、Chain of Code)
-
代码用于行动:把意图变成可执行策略(Code-as-Policies、RoboCodeX)
-
代码用于环境:把世界状态变成可查询的数据结构(WorldCoder、Code2World)
第二层:机制层
有了接口还不够,Agent 要能长期运行,需要这些机制:
-
规划:把大任务分解成小步骤(CodePlan、MapCoder)
-
内存:记住做过什么、学到什么(CodeMem、RepoCoder)
-
工具使用:调用外部 API 和服务(ToolCoder)
-
反馈控制:出错了能自动修正(AgentCoder、AdaCoder)
这一层解决的是“Agent 怎么不翻车”的问题。
第三层:多 Agent 协作层
一个 Agent 干活,多个 Agent 协作更复杂。代码作为共享工件的好处:
-
代码库是共同的工作空间
-
测试是共同的验证标准
-
执行轨迹是共同的历史记录
典型系统:MetaGPT 里,Manager 分配任务,Coder 写代码,Reviewer 审查,Tester 测试,整个流程都在代码库里留痕,谁做了什么一目了然。
这套方法已经在哪些地方用上了?
论文总结了五大应用场景,我挑几个最有意思的说说:
1. 编码助手(已经在用)
SWE-bench、OpenHands 这些系统,Agent 直接在真实代码库上修 bug、写功能。它们不是生成一段代码就完事,而是:
-
读懂整个代码库的结构
-
写测试验证修改
-
提交 PR 前自己跑 CI/CD
这就是“代码作为环境”的典型应用。

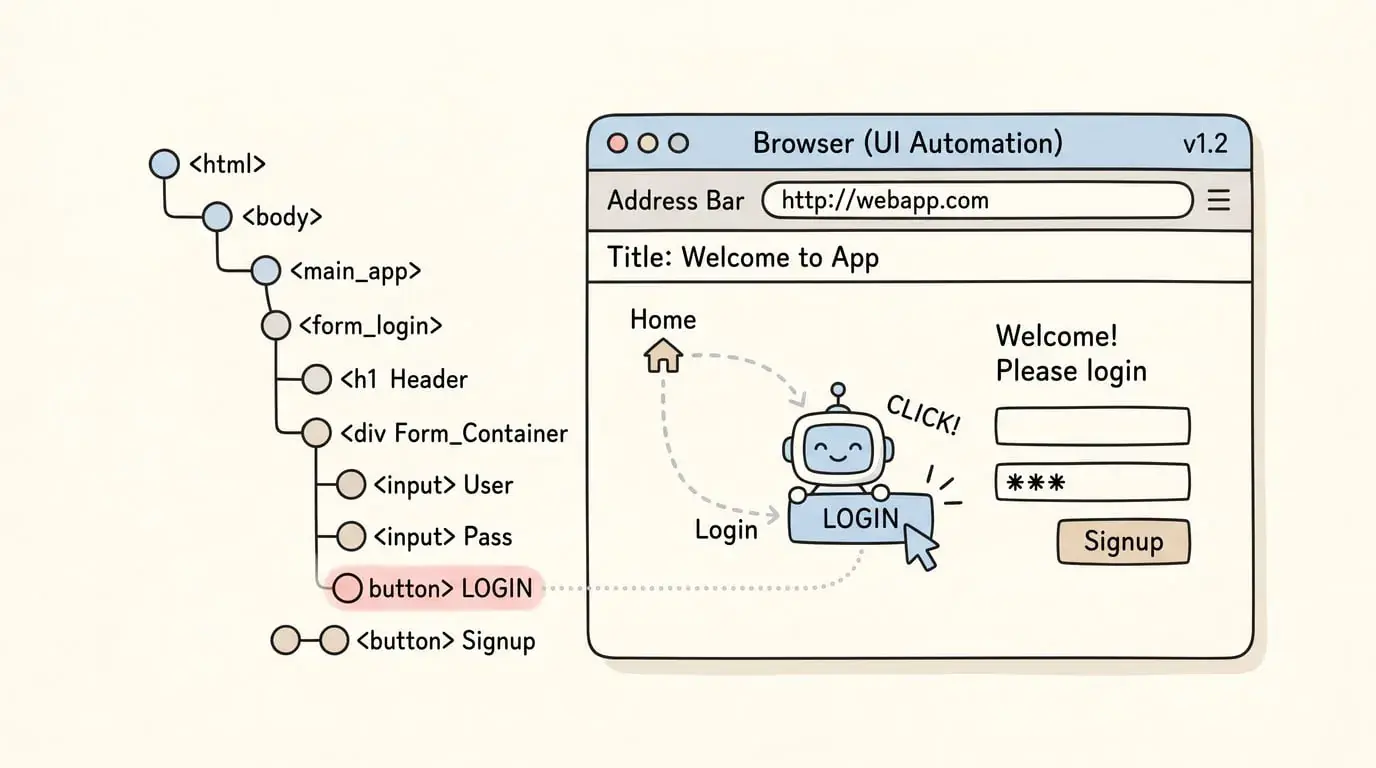
2. GUI 自动化(潜力巨大)
Mind2Web、WebArena 让 Agent 操作网页和应用界面。关键是它们把 DOM 树、可访问性 API 变成了可执行的代码表示,Agent 的每个点击、输入都能回放和验证。
坦白说,这个方向如果做好了,能干掉一大批 RPA 工具。
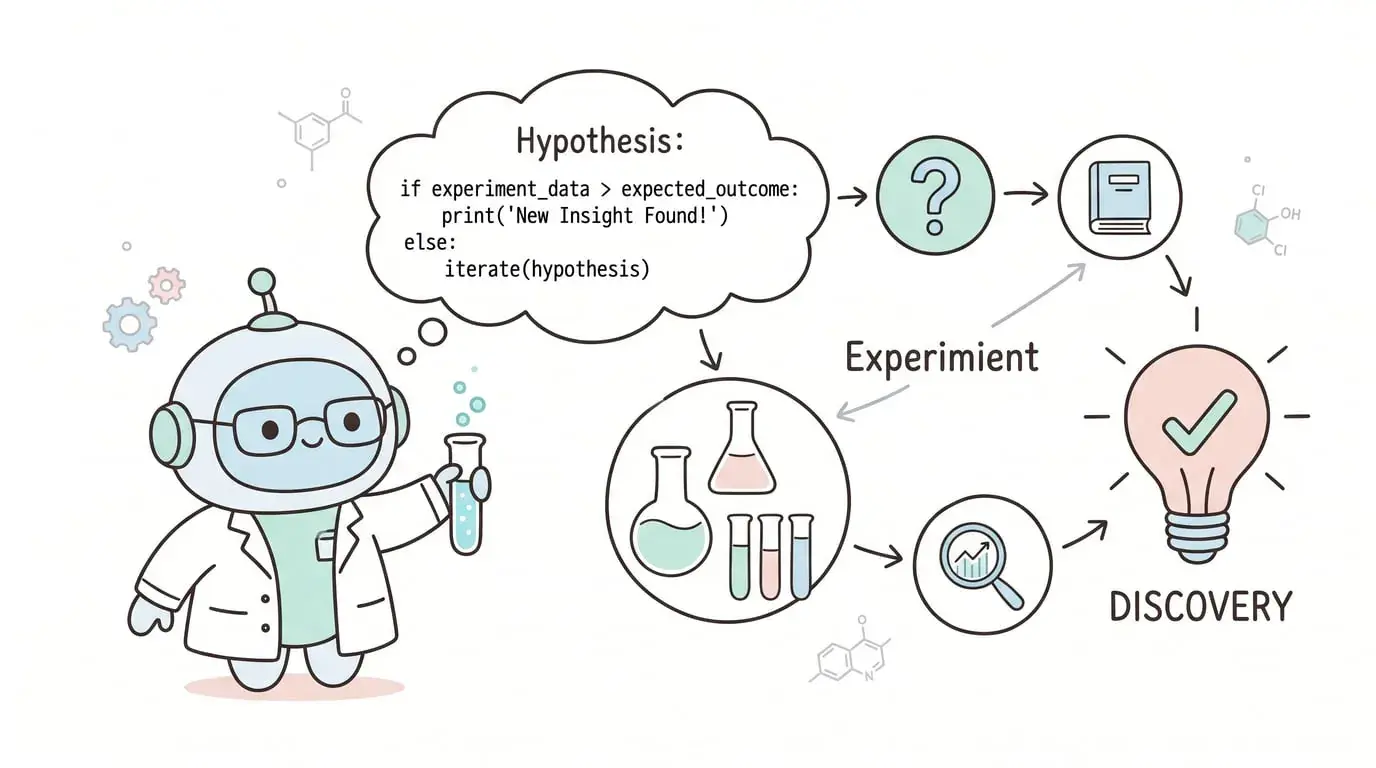
3. 科学发现(最激进)
ChemCrow 让 Agent 设计化学实验,AI Scientist 让 Agent 自己做科研。它们的共同点是:
-
假设用代码表示
-
实验流程用代码编排
-
结果用代码分析
这不是科幻,是已经在跑的系统。
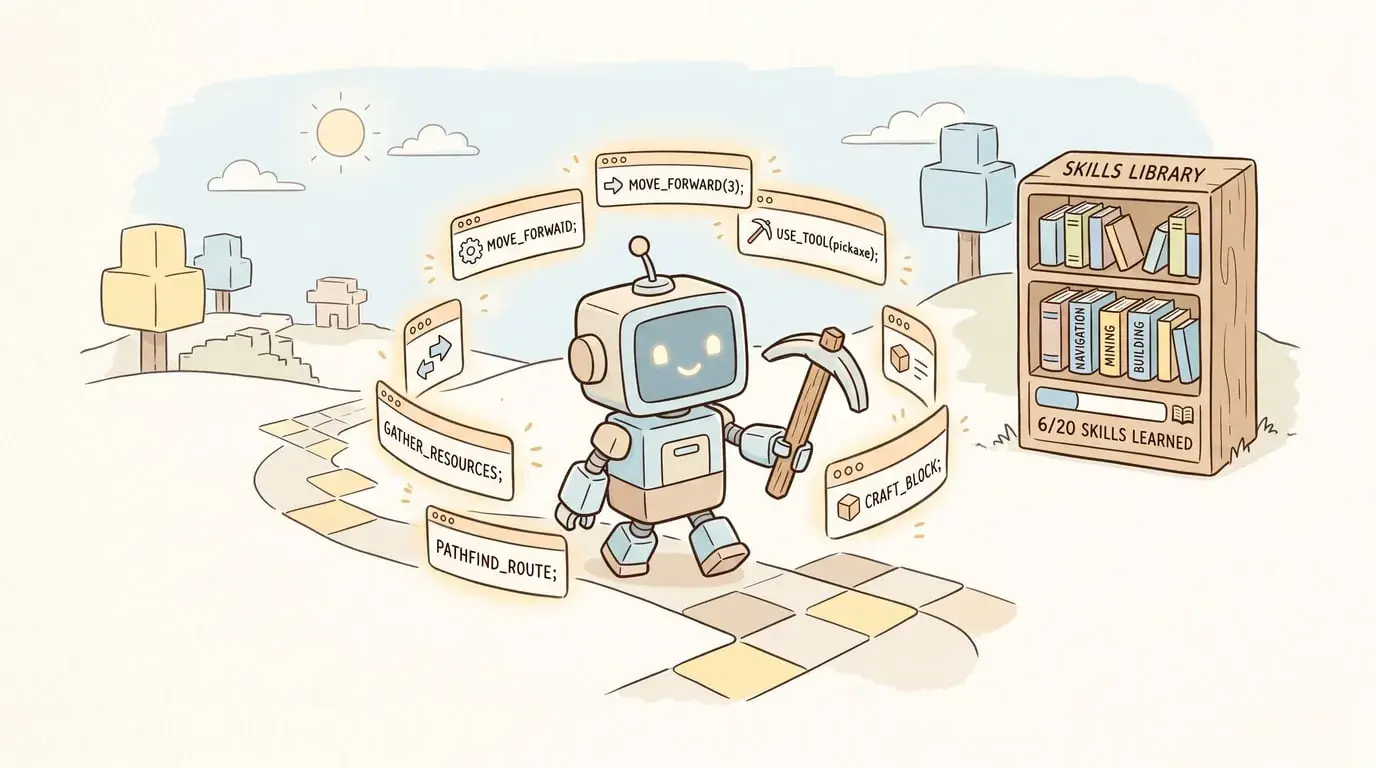
4. 具身机器人(最直观)
Voyager、SayCan、Code-as-Policies 让机器人通过代码学习技能。机器人不是被“训练”出来的,而是自己写代码、执行、调试、积累技能库。
这种范式的好处是技能可迁移、可组合、可调试,不像神经网络那样是个黑盒。
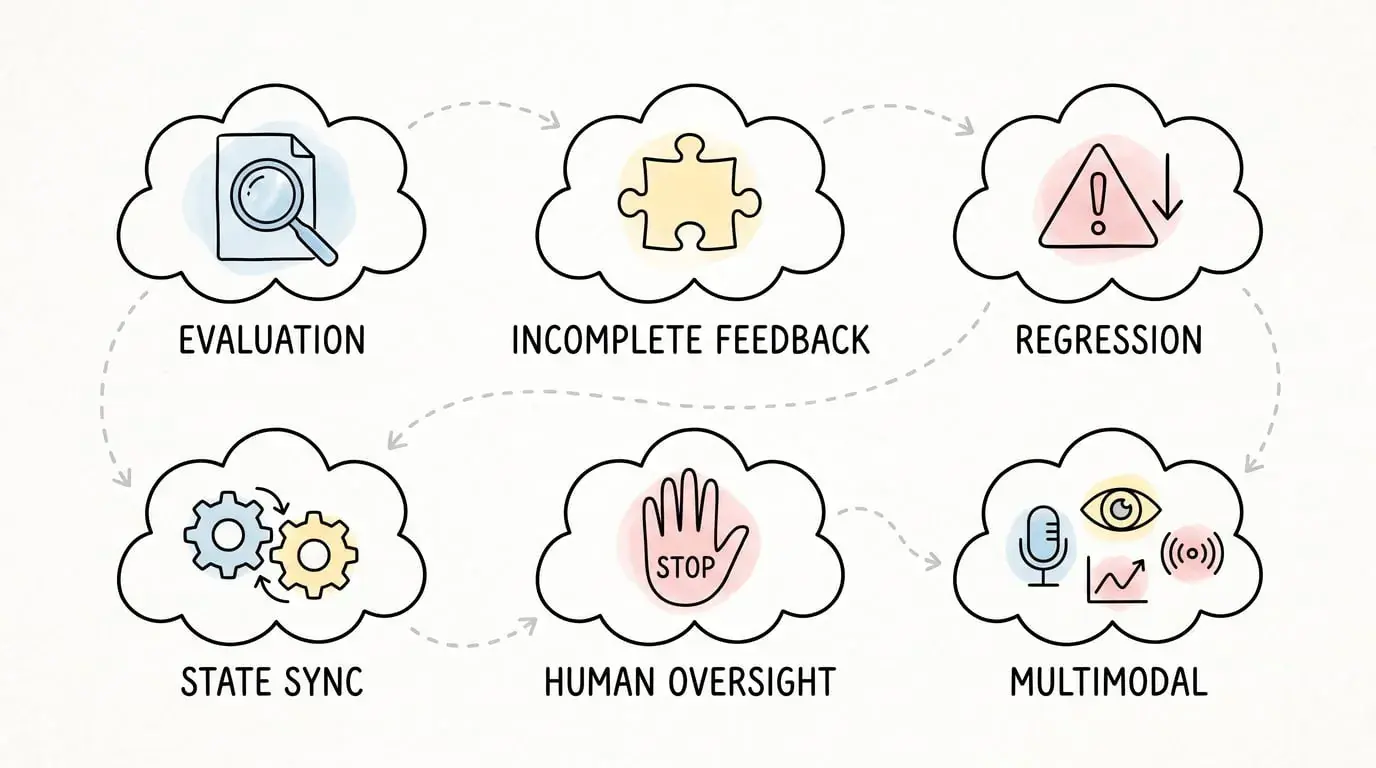
还有哪些问题没解决?
论文很诚实地指出了六大挑战,我觉得这是最有价值的部分,因为它告诉你“什么还做不到”:
1. 评估太粗糙
现在只看最终结果对不对,不看中间过程质量。就像只看考试分数,不看解题步骤。
为什么重要:Agent 可能蒙对了答案,但推理过程一塌糊涂,下次换个题就不行了。
2. 不完整反馈下的验证
很多环境你看不到全部信息,Agent 怎么知道自己做对了?
真实场景:机器人抓取物体,摄像头有盲区,Agent 怎么确认抓稳了?
3. 改进时不能引入新 bug
Agent 自己改代码,怎么保证不把原来能用的功能搞坏?
这是最难的:现在没有好的回归测试框架能自动验证 Agent 的改动。
4. 多 Agent 的状态同步
10个 Agent 同时改一个代码库,怎么保证它们看到的状态是一致的?
类比:就像多人协作编辑文档,谁的修改覆盖谁的?
5. 高风险操作的人类监督
Agent 要删数据库、发邮件、转账,必须有人类确认机制。
但问题是:怎么设计这个机制,既不让 Agent 每次都问(太烦),又不让它自己乱来(太危险)?
6. 多模态环境
现在主要是文本和代码,视觉、音频、传感器数据怎么融入这套框架?
我的看法:这可能需要重新设计“可执行性”的定义。
这篇论文为什么重要?
说白了,它回答了一个关键问题:AI Agent 的瓶颈不是模型能力,而是系统可靠性。
你的 GPT-5 再聪明,如果它的推理过程不可验证、行动不可追溯、状态不可检查,你敢让它管关键业务吗?
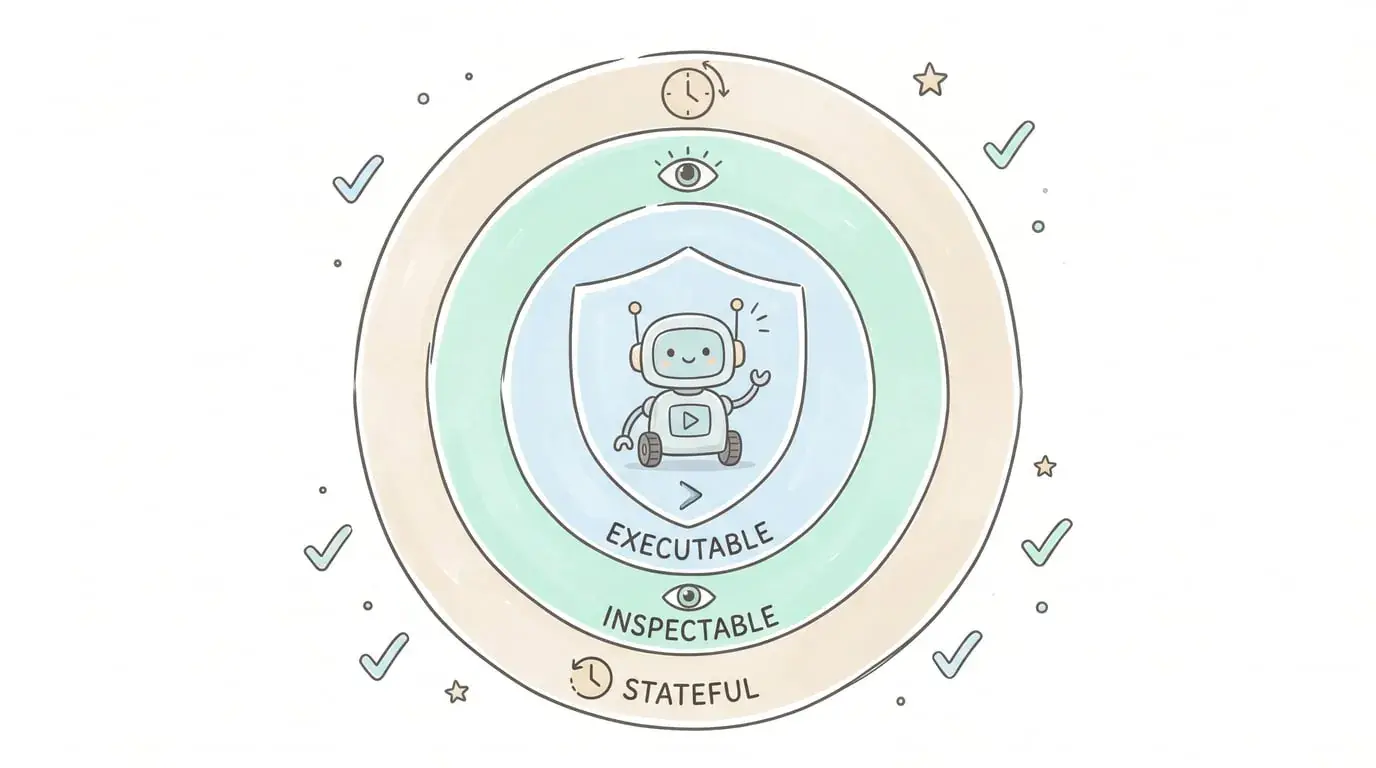
这篇论文提出的“代码作为框架”,本质上是给 Agent 加了三层保险:
-
可执行性:能跑起来验证
-
可检查性:能看到中间过程
-
有状态性:能记住做过什么
这三个特性,决定了 Agent 能不能从“Demo 玩具”变成“生产力工具”。
如果你想深入了解
这篇论文总结了 110+ 篇相关论文和 23 个系统,是目前这个领域最全面的综述。
我的建议:
-
如果你在做 Agent 系统,重点看第2章(框架接口)和第3章(框架机制)
-
如果你在做多 Agent 协作,直接跳到第4章
-
如果你想找应用场景,看第5章的五大领域
-
如果你想找研究方向,看第6章的六大挑战
论文信息:
-
标题:Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems
-
机构:伊利诺伊大学香槟分校、Meta、斯坦福大学
-
发布:2026年5月
-
GitHub:https://github.com/YennNing/Awesome-Code-as-Agent-Harness-Papers
最后说一句:如果你现在正在做 Agent 系统,不管是编码助手、自动化工具还是机器人控制,问自己三个问题:
-
你的 Agent 的推理过程能验证吗?
-
你的 Agent 的行动能追溯吗?
-
你的 Agent 的状态能检查吗?
如果三个答案都是“不能”,那你可能需要重新设计架构了。