这是我的 Harness & Loop Engineering 学习笔记系列的第一篇。目标是先把概念搞清楚——不是背定义,是真的理解这两个词在说什么、为什么重要、它们之间什么关系。
刚开始接触这两个词的时候,我其实挺困惑的。
2026 年上半年,X 上突然到处都是 Harness Engineering 和 Loop Engineering。Anthropic 的 Boris Cherny(Claude Code 的负责人)在各种场合讲 Loop;Martin Fowler 这种级别的老炮专门写了 Harness Engineering 的文章;arXiv 上甚至有人交了大型综述。感觉一夜之间大家都在聊同一件事,但每个人嘴里说的又不太一样。
我的困惑很具体:这两个词是同一件事的不同叫法吗?还是完全不同的东西?哪个更底层?我该先学哪个?
下面是我梳理完之后的理解。它不一定对,但它帮我建立了一个能往里装新知识的心智框架。
一个让我真正开始重视这件事的数据
SWE-bench。这是目前最被认可的 AI 编程能力测试:给模型一个真实的 GitHub issue,让它自动修 bug。不是写 toy code,是修真实项目里的真实问题。2024 年 OpenAI 还发布了一个经过人类验证的精简版——SWE-bench Verified,从原始题库里筛出 500 道确认可评估的题目,后来成了行业标准的比较基准。
2024 年初,最好的模型在 SWE-bench 原始版上得分不到 20%(Devin 当时以 13.86% 的成绩已经是最高水平)。到 2025 年底,在更严格的 SWE-bench Verified 上,Devin 和 Claude Code 把成绩推到了 60% 以上。
这中间模型本身当然也在进步——从 GPT-4 到 GPT-4o,从 Claude 3 到 Claude 3.5 Sonnet 再到 Claude 4,每一代推理能力都在变强。但 Anthropic 内部实验显示了一个更有意思的现象:同等模型水平下,有没有完整的 Harness 和精心设计的 Loop,表现差距可以大到几十分。 换句话说,模型进步是必要条件,但不是充分条件——从「能推理」到「能干活」,中间那一步靠的是工程。
这让我意识到一个重要的点:我们以前谈 AI 能力,几乎默认就是在谈模型能力。但 SWE-bench 的数据和这两年的实践说明,同一个模型套上不同的 Harness 和 Loop,表现可以天差地别。模型不是瓶颈了,工程才是新的主战场。
这大概也是为什么 2026 年这两个概念突然爆发。大家终于发现,模型不是瓶颈了。工程才是。
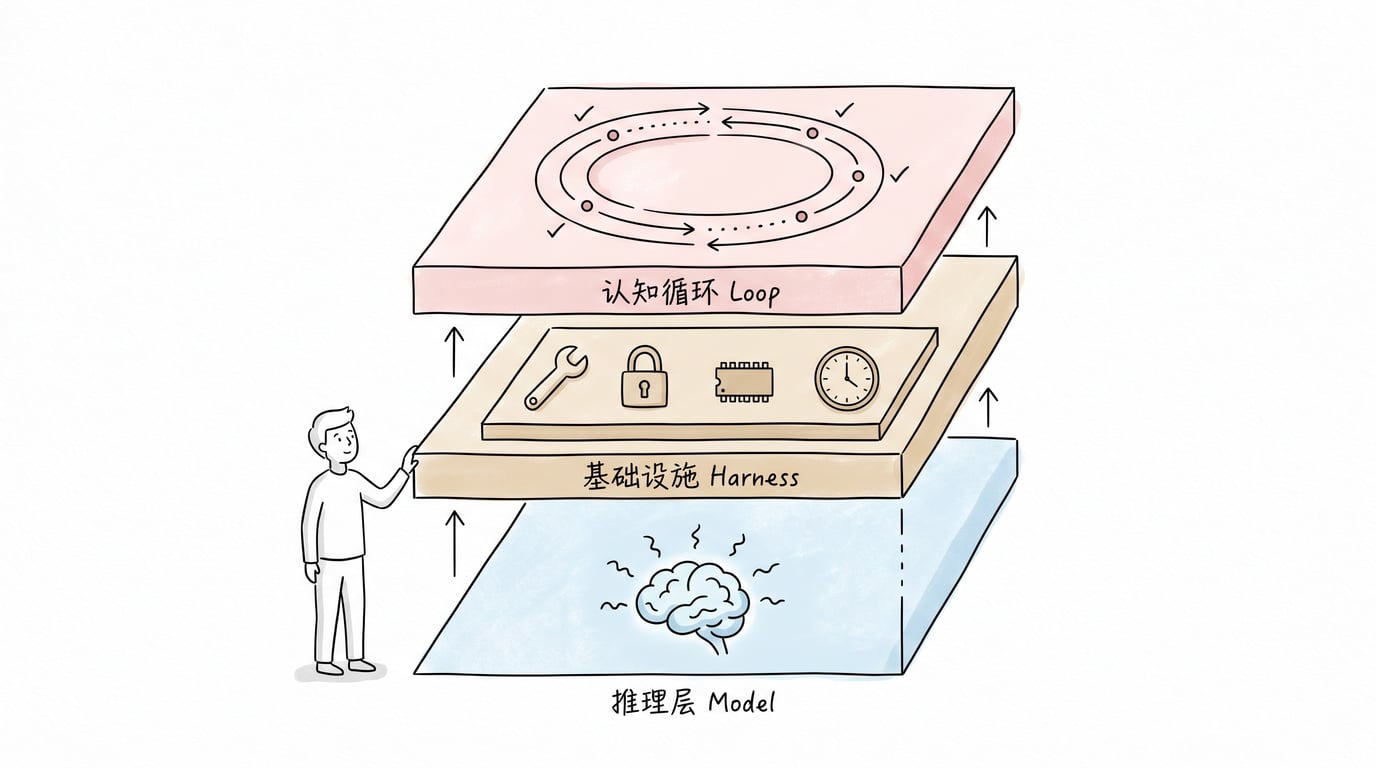
Harness Engineering:模型之外的“一切”
Martin Fowler 那篇文章给了一个我特别喜欢的定义,简单到粗暴:Harness 就是 Agent 除了模型之外的一切。
第一次看到这个定义我觉得他在偷懒。但越想越觉得对。你想想,一个 Agent 真正在干活的时候,模型只负责推理。剩下的全是工程问题:
它能用什么工具?能读文件吗?能跑命令吗?能调 API 吗?——这不是模型决定的,是 Harness 配置的。
它能删你的文件吗?遇到危险操作它会停吗?——模型自己根本没有“危险”这个概念,这层判断必须在 Harness 里做。
它一次能记住多少东西?中间断掉了怎么办?多个 Agent 同时跑怎么不打架?——全是 Harness 的范围。
我后来把 Harness 的核心职责归纳成四个维度,这个归纳帮我理清了很多东西:
第一,工具——Agent 的手。 Claude Code 的设计给了我一个很好的参考:文件操作、终端命令、网络请求,每种工具都有自己的权限层级。Agent 不是想用就能用的,每次要调用工具,Harness 要先检查:你有权限吗?这个操作安全吗?这种设计思路跟操作系统里的系统调用有点像——你能做什么,取决于内核给你开了什么接口。
第二,安全边界——Agent 的围栏。 这个我觉得是 Harness Engineering 里最被低估的部分。模型不会说“不”,你让它删库它真的会去试。X 上有工程师用过一个我很认同的比喻“沙箱属性”——Harness 就是画一个圈,告诉 Agent:圈里随便跑,圈外碰都别碰。怎么画这个圈、画多大、画在哪儿,全是工程决策。
第三,内存管理——Agent 的工作记忆。 Agent 的上下文窗口是有限的,这是一个硬约束。一个 bug 修复任务可能涉及几十个文件、上百次工具调用,产生的信息量远超任何模型的上下文窗口。Harness 要像一个熟练的助手:把跟当前步骤相关的信息放在桌上,把暂时用不上的收到抽屉里,把彻底没用的扔掉。放错了,Agent 就断片;扔早了,Agent 就得回头重来。
第四,生命周期——Agent 从生到死。 一个任务跑几分钟到几小时,中间可能断掉、可能出错、可能需要暂停等人确认。Harness 管这一切:启动、暂停、恢复、错误处理、结果交付、资源回收。
把这四个维度串起来,Harness 的本质就好懂了:它就是 Agent 的运行时,一个给模型配的操作系统。操作系统决定了程序能跑多快、能访问什么资源、崩溃了怎么办——Harness 对 Agent 做的是完全一样的事。
Loop Engineering:让 Agent 学会“边做边想”
Harness 给了 Agent 手脚,但一个手脚齐全的人不一定会走路。走路需要节奏、需要看路、需要踩空了能稳住。
这就是 Loop Engineering 的领域。
Addy Osmani 给了我最清晰的定义:Loop Engineering 是设计一个系统,让 Agent 在干活的过程中持续地自己给自己出题、自己检查答案、自己纠正方向。它不是“输入问题 → 输出答案”的一条直线,而是一个闭环:拆目标 → 做一步 → 看结果 → 发现不对 → 调整 → 再做。
我第一次理解这个概念的时候,想到的是自己修 bug 的过程。没人是一次性想清楚所有步骤再动手的——都是看日志、猜原因、改一下、跑测试、没通过、再看日志、再猜、再改。这个过程天然就是循环的。Loop Engineering 就是把这种人类的“边做边想”模式,工程设计到 Agent 里面。
拆开来看也是四个维度:
目标拆解。 拿到“修好这个 CI 失败”的任务,Agent 不能直接冲进去改代码。它得先想:第一步读日志、第二步定位失败点、第三步分析原因、第四步改代码、第五步验证。拆得好,后面的循环越走越顺;拆歪了,整个循环都在错误的方向上打转。这其实跟人类做项目拆 WBS 是一个道理,但 AI 没有项目管理的经验直觉,拆解逻辑必须被设计进去。
验证反馈。 每走一步,必须检查。“改完了”不算完——测试过了吗?lint 报了吗?有没有把别的地方搞坏?这是 Loop 的“眼睛”。Stripe 的 Minions 系统把这个做到了极致:Agent 每产出一个东西,先得过验证 gate,验证不通过就回到上一步,根本不让脏数据流进下一步。我开始觉得这会不会太繁琐,后来想明白了:AI 模型不比人类工程师,人类知道什么时候该偷懒跳过检查,AI 不会。所以验证不能靠自觉,要靠机制。
失败恢复。 Loop 之所以叫 Loop 不叫 Pipeline,就是因为会回头。改完代码测试没通过?不是“再试一次”,而是带着新的错误信息重新推理——刚才哪个假设是错的?是不是漏看了跨文件依赖?好的 Loop 设计会区分不同类型的失败:编译错误是确定性信号,直接定位就行;逻辑错误需要重新理解问题,可能要换方向;超时或网络问题可能是外部因素,策略又不一样。
自我提示。 这是 Loop Engineering 里最让我觉得有意思的概念。传统的 prompt 是人写的,Loop 里的 prompt 是 Agent 自己写的——每一步结束之后,它根据上一步的结果给自己写下一步的指令。“刚才改了 A 文件,单元测试过了但集成测试挂了,错误指向 B 模块。我需要:第一,读 B 模块的代码;第二,理解 A 和 B 之间的调用关系;第三,判断问题在 A 的改动还是 B 本身的逻辑。”这种自我提示的质量,直接决定了 Agent 是越跑越聪明还是原地打转。
Boris Cherny 说过一个观点我很认同:Claude Code 真正厉害的不是接了多强的模型,而是它的 Loop 设计——怎么在多轮交互里保持方向不丢、怎么从错误里提取真正有用的信息、怎么判断什么时候该认栽换一条路。这些都是 Loop 的工程问题,不是模型的推理问题。
一张图看清关系
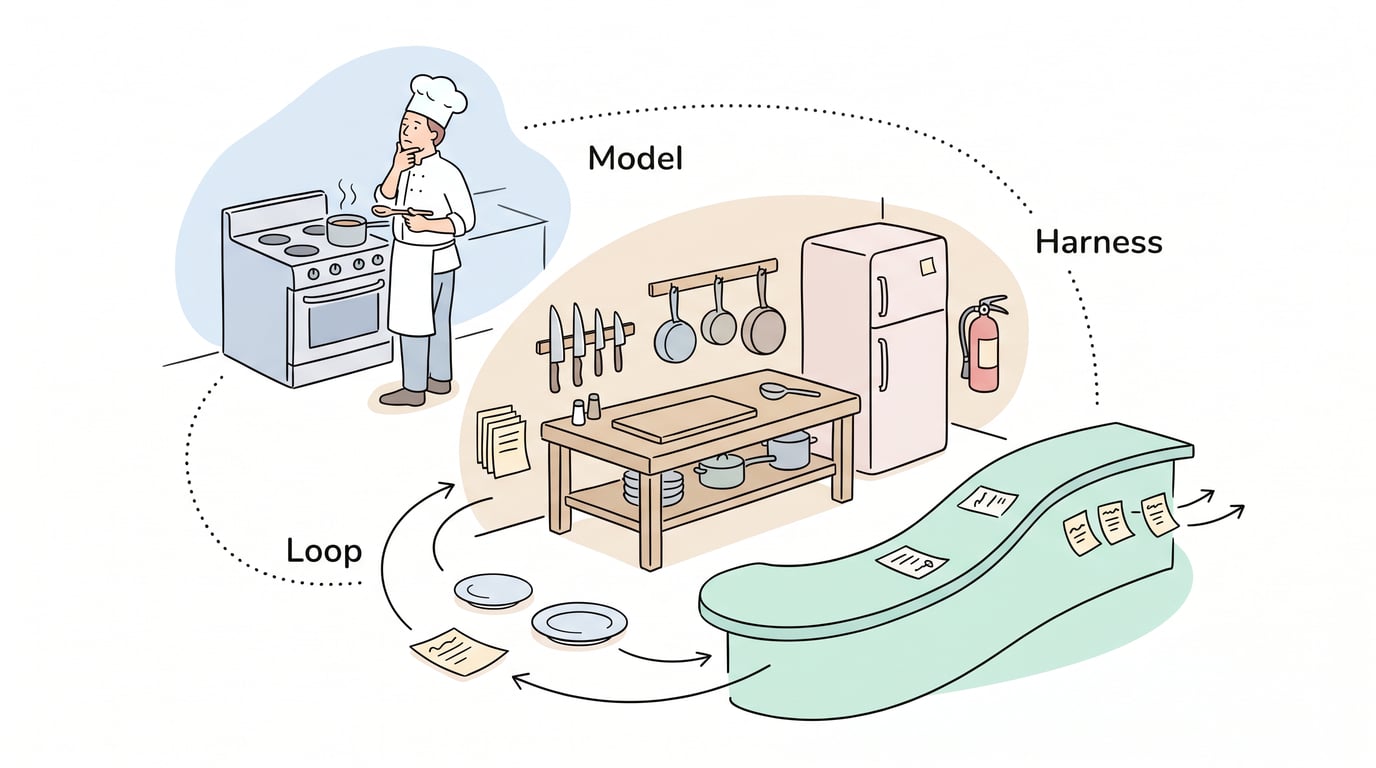
梳理到这里,两个概念的关系其实挺清楚的。但我觉得用一个比喻讲会更直观:
想象你要开一家餐馆。
模型 是你的主厨——有手艺、有经验、能判断菜好不好吃。这是核心能力的天花板。
Harness 是你的厨房——灶台、刀具、冰箱、排风系统。厨房建得好,主厨才能发挥;厨房缺东西或者布局反人类,主厨再厉害也只能干瞪眼。而且厨房有安全规范——燃气阀门在哪、灭火器摆哪、什么刀谁才能碰——这就是 Harness 的权限和安全边界。
Loop 是你的出餐流程——前菜什么时候上、主菜什么时候炒、哪道菜要先过摆盘检查才能端出去、客人退菜了怎么处理。这是执行层的事。
一个好的餐馆,三层都得在线。主厨不行,菜本身不行;厨房拉胯,主厨有劲使不出;流程混乱,菜做对了也送不到客人桌上。
换成公式:
Agent = Model+ Harness + Loop
模型决定上限,但 Harness 和 Loop 决定你到底能兑现多少。
一个反直觉的事实
我在查资料的过程中看到一个让我挺震撼的数据(据 X 上的 @_vmlops 引用 Anthropic 内部实验的说法):同一个中等水平的模型,配上完整 Harness 和精心设计的 Loop,在 SWE-bench 上的表现可以超过裸跑的顶级模型。
这意味着什么?意味着在 2026 年的实践中,给工程投精力,回报可能比换模型更高。
这不是说模型不重要。而是说很多人都搞反了——大家拼命追最新最强的模型,但 Harness 和 Loop 的工程债务越欠越多。换个类比:买了一台法拉利的发动机(最好的模型),塞进一辆没调过底盘的破车里(没有好 Harness),让一个没上过赛道的司机开(没有好 Loop),结果可能还跑不过一台思域。
这大概就是为什么 2026 年 Harness Engineering 和 Loop Engineering 会变成独立的概念被单独讨论。它们不再是“模型之外顺便搞一下”的东西,而是跟模型同等重要的工程学科。
后续
这篇建立了一个最基本的框架。我把它写下来的目的不是“学会”,而是先有一个能装新知识的结构——后面读论文、看案例、研究具体系统的时候,每个知识点都能准确地放进三层模型里的某个位置。
接下去的计划:
-
第二篇:拆 Harness——工具集成怎么设计?安全边界怎么划?上下文管理有哪些策略?
-
第三篇:拆 Loop——验证机制怎么搭?失败怎么分类处理?自我提示怎么设计才有效?
-
第四篇:案例分析——拿 Claude Code 和 Stripe Minions 做完整拆解,用三层模型对照着看
-
第五篇:论文精读——arXiv 上那三篇核心论文,到底贡献了什么,还有什么没解决
先写到这。下一站,钻进 Harness 的内部看看。