系列第四篇。前三篇分别建立了三层模型(Model + Harness + Loop)并深入拆了 Harness 和 Loop。这篇把三层模型叠起来,完整拆解两个目前最成熟的 Agent 系统,看理论和实践怎么对上。
学东西最怕只停留在概念层。Harness 的四个维度、Loop 的三个齿轮、三层心智模型——这些框架的价值在于,扔一个真实系统到你面前,你能用框架把它拆清楚、看出设计好在哪里、什么选择是不得已。
这篇拿两个系统练手。Claude Code 和 Stripe Minions,一个偏个人开发者场景,一个偏企业内部大规模部署,思路不同但很多底层设计在往同一个方向收敛。
Claude Code:一个人的 Agent 军团
Claude Code 是 Anthropic 的终端 AI 编程工具,Boris Cherny 带队做的。它的设计哲学很有意思:不是做一个「全自动写代码的机器人」,而是做一个「你能信任的 AI 工程师」。
模型层
Claude Code 底层跑的是 Anthropic 的 Claude 系列模型——从 Claude 3.5 Sonnet 到 Claude Opus 4.x 系列。模型选择上有个值得注意的设计:主会话跑最强模型(Opus),做高层推理和架构判断;子 Agent 跑稍弱的模型(Sonnet 甚至 Haiku),做具体实现和搜索。这个分层不是 Anthropic 一开始就设计的,是工程团队在实践中摸索出来的——重型推理和轻量执行分开,既省 token 又让主会话的上下文保持干净。
Harness 层
Claude Code 的 Harness 设计是典型的「克制胜过功能堆砌」。四个维度拆开看:
工具集。 保持得很小——文件读写、终端命令、网络搜索、Git 操作。工具不在多,在每一样都可靠。对比一些开源 Agent 框架动辄几十上百个工具,Claude Code 的选择是「少给,但每个都给透」。工具描述也讲究——用模型自己做工具发现,而不是人手写一份可能过期的文档。
安全边界。 分层权限系统 + 沙箱隔离。Claude Code 的权限是 deny-first 的——默认不信任任何操作,权限分级之后低风险自动放行、高风险等人确认。arXiv 上那篇 Claude Code 架构论文(2604.14228)透露了一个细节:用户约 93% 的权限提示都被批准了。这个数字暴露了一个问题——审批疲劳让「每次问人」实际上不是安全机制。所以 Anthropic 没在审批上加更多提醒,而是把安全推到架构层:独立沙箱、auto-mode 分类器、deny-first 评估。安全不能靠人的警惕性,要靠架构。
上下文管理。 这是 Claude Code 最值得细看的设计之一。它的上下文管理有一个专门的 compaction pipeline——当上下文逼近窗口上限时,不是简单截断,而是把旧消息压缩成摘要。更高级的是 CLAUDE.md 这种项目级持久记忆——跨会话的知识不丢失。Boris Cherny 提过一个做法:Agent 犯了重复性错误,就让 Agent 把教训写进 CLAUDE.md,这样未来所有会话都能受益。这是一个跨任务的学习循环。
生命周期。 Claude Code 支持持久化会话状态——一个任务可以跨多次启动、暂停、恢复。worktree 机制让多个 Agent 在独立的 git worktree 上并行工作,互不冲突。跑完之后 Harness 负责合并和清理。Boris Cherny 说过 worktree 是「目前最大的生产力解锁」——把「多 Agent 并发」的复杂度从推理层搬到了工程层。
Loop 层
Claude Code 的 Loop 设计经历了从非正式到工程化的快速演变。2026 年 5 月发布的 /goal 命令是一个分水岭——之前你要手动跑 Agent、看结果、再跑、再看;之后你只需要设定一个可验证的目标条件(「所有测试通过」「CI 变绿」),Agent 自己循环跑到达标。
Loop 的几个关键设计:
验证用了独立模型。 /goal 命令不只是盲跑——它用单独的模型来评估每次运行的结果是否满足目标条件。这解决了「自己给自己打分」的信任问题。Agent 产出的代码和测试结果,由一个独立的评估者来判断是否达标。
子 Agent 做任务分解。 Claude Code 的 subagent 系统是 Loop 的骨架。一个复杂任务被拆成多个子任务
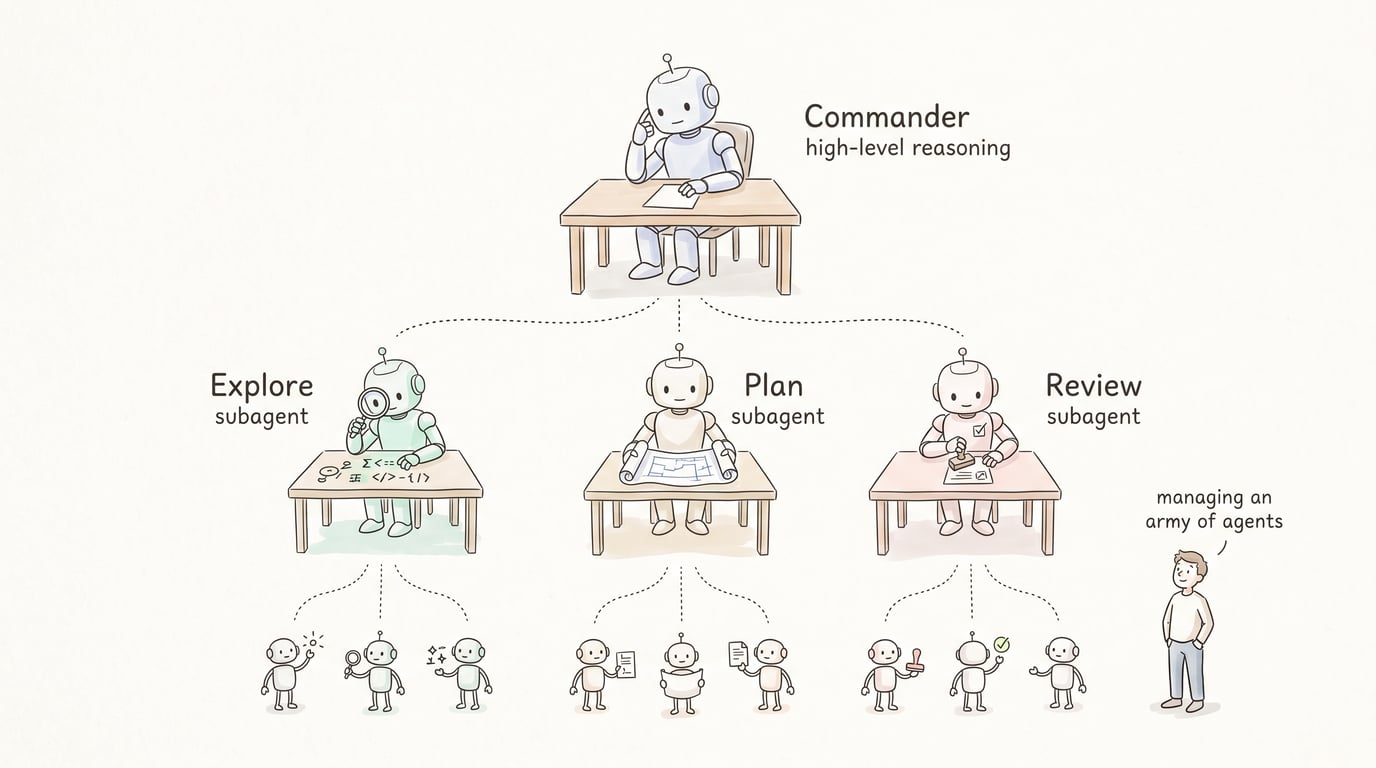
,每个子 Agent 在自己的隔离上下文里跑——Explore 负责搜索和理解代码、Plan 负责规划、专门的 reviewer 负责验证。Boris Cherny 说过他现在的工作模式是「管一支 Agent 军队」——Agent 调度 Agent,层层分解。
跨 Loop 学习。 CLAUDE.md 不只是上下文管理的工具,它也是 Loop 的学习机制。每次失败之后,教训被持久化;下次跑类似任务的时候,Agent 自动带着之前的经验进来。这个设计把一个「单次循环」升级成了「持续进化的循环系统」。
Boris Cherny 在 2026 年 6 月说了一句很有代表性的话:「/loop 是我目前最喜欢的功能。」从一个人盯着 Agent 跑,到设定目标、Agent 自己跑到达标——这个变化看起来只是加了一个命令,背后是一整套 Loop 基础设施的搭建。
Stripe Minions:企业级 Agent 舰队
Stripe Minions 的定位和 Claude Code 完全不同。Claude Code 是一个人用的工具,Minions 是企业内部的 Agent 基础设施——每周自动生成和合并超过 1,300 个 PR。规模决定了设计思路完全不同。
模型层
Minions 的底层模型没有公开披露具体型号,从公开信息来看用的是主流 LLM(大概率包含 GPT 和 Claude 系列)。但模型选择不是 Minions 的核心故事——Stripe 更关注的是 Harness 和 Loop,因为规模上去之后,模型之间的差距被工程差距盖过了。
Harness 层
Minions 的 Harness 设计有一条清晰的主线:用架构做安全,而不是用规则做安全。 四个维度拆开看:
工具集。 比 Claude Code 大得多。Stripe 建了一个叫 Toolshed 的中央 MCP 服务器,整合了约 500 个内部工具和 SaaS 集成——从代码仓库到 CI 系统到项目管理工具,全接在一起。但不是每个 Minion 都能用全部——具体到某个任务,只暴露相关的工具子集。规模大但权限紧,这个平衡做得很有意思。
安全边界。 这是 Minions 最值得学的设计。每个 Minion 任务跑在一个叫 Devbox 的独立 AWS EC2 VM 里,VM 启动约 10 秒,预装好代码和服务。关键决策:这些 VM 完全没有网络访问权限,也完全碰不到生产环境。 隔离本身就是权限系统
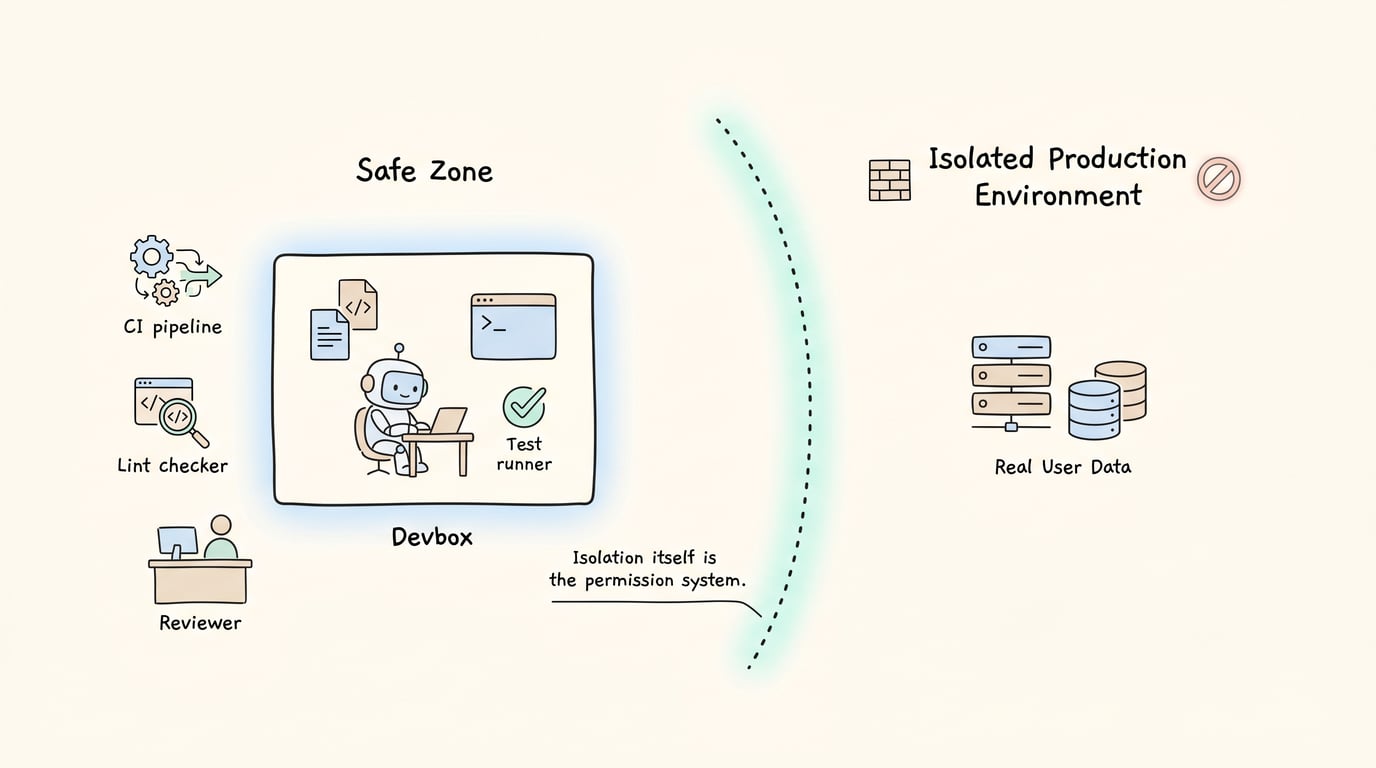
——因为 Agent 根本到不了生产环境,所以不需要在每一步检查「你能不能碰生产环境」。这是 Martin Fowler 框架里「用架构做安全」的极致体现。
上下文管理。 Minions 的每个任务有独立的上下文窗口,任务之间不共享状态(除非显式持久化)。这种设计跟 Claude Code 的跨会话记忆完全不同——Minions 选择的是「每次任务都是干净的」,降低跨任务污染的风险。
生命周期。 Minions 的 blueprint 系统是生命周期管理的核心。每个 blueprint 是一套预定义的工作流模板——从任务触发(Slack 标签、bug report、feature request)到最终 PR 提交,每一步都有明确的输入输出和状态转移。工程师可以同时并行跑 5 到 10 个 Minion,不用担心数据泄露或生产事故。
Loop 层
Minions 的 Loop 设计跟 Claude Code 有共同的语言,但实现方式完全不同。
验证用硬 gate,不用模型判断。 这是 Minions 和 Claude Code 最大的设计差异。Claude Code 的 /goal 用独立模型做评估,Minions 用的是确定性 gate——编译 gate、测试 gate、lint gate,每一步都是硬的,不过就回退。为什么?Stripe 的规模意味着每天几百个 PR,如果用模型做验证,延迟和成本都扛不住。硬 gate 快、便宜、绝对可信。能用机器判断的事,绝对不让模型判断。
混合工作流。 Minions 的 blueprint 把确定性节点(编译、测试、lint、类型检查)和 Agent 节点(推理、代码生成、决策)交替排列。Agent 产出一个东西,先过确定性验证;验证过了,Agent 才进入下一步。这个设计把「验证不是最后一步,是每一步」做到了工程层。
人在最外层。 Minions 的最终 gate 是人类 review。所有 AI 生成的代码,在合并之前都要经过人类工程师的 review。这不是因为不信任 Agent——恰恰相反,Stripe 的 Agent 已经能做到端到端完成任务——而是因为这个系统的设计哲学是「Agent 负责产出,人负责决策」。
并排对比:同一个问题,两种解法
把两个系统放在一起,能看到一些有意思的异同:
| 维度 | Claude Code | Stripe Minions |
|---|---|---|
| 使用场景 | 个人开发者 | 企业内部大规模部署 |
| 模型策略 | 主会话用最强模型,子 Agent 用轻量模型 | 模型不公开披露,工程重于模型 |
| 工具数量 | 克制(~10 个核心工具) | 大规模(~500 个 MCP 工具,按需暴露) |
| 安全策略 | 分层权限 + 沙箱 + deny-first | 完全隔离 VM,隔离即权限 |
| 上下文管理 | 跨会话持久化(CLAUDE.md)+ compaction pipeline | 每次任务干净隔离,跨任务不共享 |
| 验证策略 | 独立模型做结果评估(/goal) | 硬 gate(编译/测试/lint),不用模型判断 |
| Loop 风格 | /loop + /goal + subagent 树 | blueprint(确定性节点 + Agent 节点交替) |
| 人机关系 | 人设定目标,Agent 自己跑 | Agent 产出,人做最后一关 review |
最大的收敛点:两个系统都在把「安全性」从规则层推到架构层。 Claude Code 的 deny-first + 沙箱,Minions 的完全隔离 VM——思路不同,但底层原则一致:Agent 能做的事应该由架构决定,不是由模型判断决定。
最大的分歧点:验证策略。 Claude Code 用 AI 做验证,Minions 用硬 gate。这不只是技术选择,是场景决定的——个人开发者能接受 AI 验证的延迟和偶尔的偏差,Stripe 的规模要求验证必须快、必须绝对可信。
我能从这两个系统学到什么
拆完之后有三个收获,我觉得比具体的技术细节更有价值:
第一,Harness 和 Loop 的设计是场景驱动的。 Claude Code 和 Minions 在很多维度上做了完全相反的选择,但各自在自己的场景里都是对的。工具给多给少、验证用 AI 还是硬 gate、上下文是持久化还是隔离——没有标准答案,只有合适的答案。
第二,安全必须推到架构层。 无论是 Claude Code 的 93% 审批通过率数据,还是 Stripe 的「隔离即权限」设计,都在说同一件事:安全不能靠人在每一次操作时做判断。人会有审批疲劳,模型不会拒绝危险指令。安全必须在架构层解决——沙箱、隔离、硬 gate。
第三,Loop 正在从手段变成产品。 2026 年 5-6 月,Claude Code 的 /loop 和 /goal、Codex 的 Automations,都不是简单的功能添加——它们是把「循环执行」从一种用户自己写脚本的技巧,变成了产品内置的一等公民。Loop 不再是「你自己想办法搭」,而是「我们给你搭好了,你只需要设定目标」。
下一篇预告:最后一篇,精读三篇 arXiv 核心论文——Code as Agent Harness(2605.18747)、Agentic Harness Engineering(2604.25850)、Architectural Design Decisions(2604.18071)——提炼核心贡献、方法差异和开放问题。把理论框架跟学术前沿接上。