📌 本文是「AI 时代的编码新范式」系列的第 3 篇。全系列共 9 篇,基于 43 篇行业文献、学术论文与一线实践报告,探讨 Spec-Driven Development 如何在 AI Agent 时代从边缘实践变为工程的基础设施。每篇可独立阅读。
2023 年,微软研究院做了一个干净利落的实验:找一批开发者,让他们用 JavaScript 实现一个 HTTP server,越快越好。一半人可以用 GitHub Copilot,另一半不能。
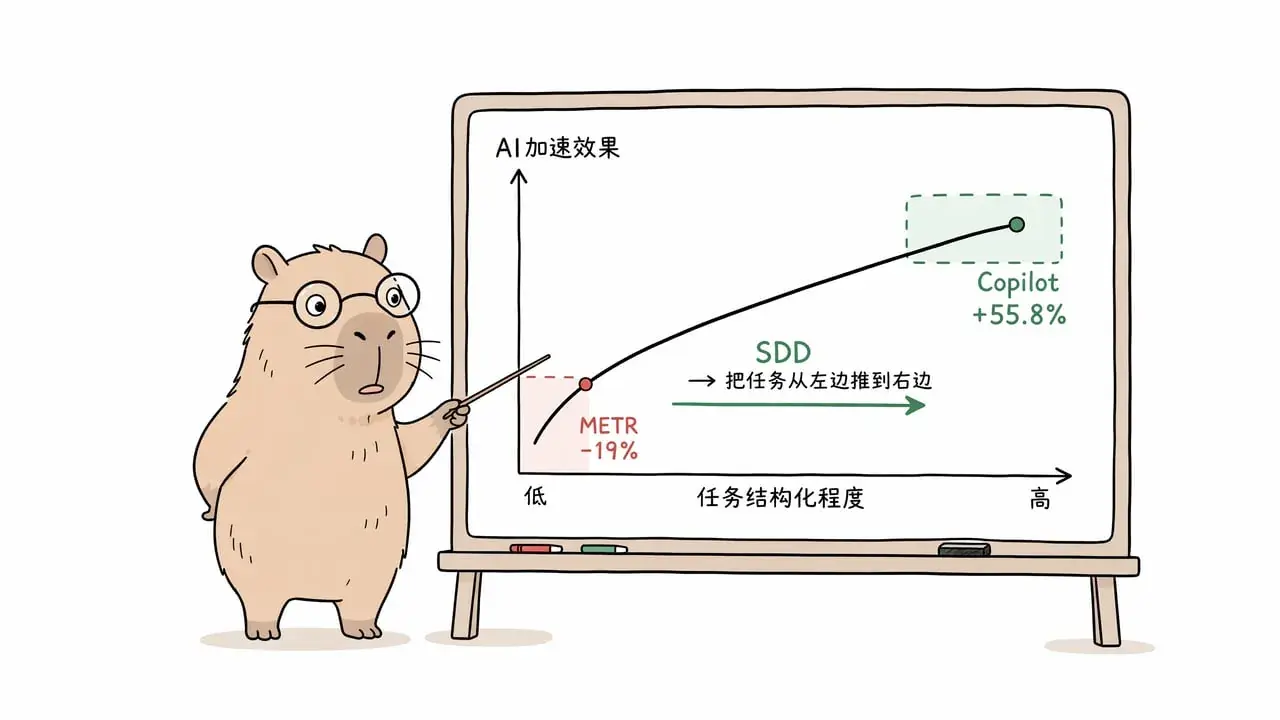
用 Copilot 的那组快了 55.8%。
2025 年,独立研究机构 METR 做了另一个实验:找 16 个经验丰富的开源开发者——平均 5 年该项目的贡献经验——让他们在自己的仓库里修 bug、加功能、做重构。随机分配,一半任务可以用 AI 工具,另一半不能。
用 AI 的那组慢了 19%。
同一个 AI。两个实验。一个飞起来,一个陷进去。这不是「有人说快有人说慢」的罗生门——两个实验都是对的。它们只是测了两种完全不同的使用场景。而这两个数字之间的落差,恰好就是 SDD 存在的全部理由。
先看快的那个:AI 在理想条件下能有多快
Copilot 实验的设计者很清楚自己在干什么。他们没有让开发者去「优化一下这段代码」或者「帮我看看这个 bug」——他们选的是一个教科书级别的原子任务:实现一个 HTTP server。输入边界是「HTTP 协议」这个公开标准,输出边界是「能响应请求的服务端程序」。没有歧义,没有隐式上下文,没有需要跟现有代码风格对齐的约束。
在这种条件下,Copilot 几乎是在替开发者写样板代码。开发者负责想清楚要什么,Copilot 负责打字。快了 55.8%,在这个任务设定下完全合理——不是 AI 有多聪明,而是任务本身就不需要太多「理解」,只需要「翻译」。
OpenAI 自己的内部实验把这个逻辑推到了极限。2025 年 8 月,一个三人工程团队启动了一个新项目——一个内部软件产品的 beta 版。他们给自己定了一条铁律:零行手动代码。所有代码,从应用逻辑到测试到 CI 配置到文档到内部工具,全部由 Codex 生成。
五人月后,仓库里躺着大约一百万行代码。一千五百个 PR,平均每个工程师每天 3.5 个 PR。产品有日常内部用户和外部 alpha 测试者。OpenAI 估计,如果手写,需要十倍的时间。
但如果你以为这个团队只是对着终端说「帮我做一个产品」然后去喝咖啡,那就错过了整件事的核心。
他们做的第一件事,是让 Codex 自己生成了一份 AGENTS.md——告诉 Agent 这个仓库怎么用、规则是什么、文档在哪。他们建了一整套 harness:结构化的 docs 目录、带验证状态和核心设计信念的设计文档、分层的架构文档、按功能域和架构层打分的质量文档。任务计划是第一等工件——小的用轻量计划,复杂的用带进度日志和决策日志的 execution plan,全部签入仓库。还有专门的「文档园艺」Agent 定期扫描过时文档,自动提修 PR。
他们管这套东西叫「progressive disclosure」:Agent 启动时看到的是一份一百行的目录,而不是一千页的手册。Agent 被教会在需要的时候自己去翻更深层的文档,而不是一次性把所有信息塞进上下文。
用他们自己的话说:「早期进展比我们预期的慢——不是因为 Codex 不行,而是环境没有被充分指定。Agent 缺少工具、抽象和内部结构来完成高层的目标。」
换句话说,他们做的第一件事不是写代码。他们做的第一件事是把每一个任务变得边界清晰、上下文完整、验收标准可验证。
然后 Codex 飞起来了。

再看慢的那个:AI 在现实世界里是怎么拖后腿的
METR 的实验从设计上就跟 Copilot 实验站在另一个极端。
十六个开发者,来自平均拥有两万两千颗 GitHub star 的大仓库——例如 PostgreSQL、pandas、scikit-learn 这种级别的项目——每个仓库超过一百万行代码。开发者平均在这个项目上贡献了五年。他们对这些代码库的了解,远远超过任何 AI 工具可能从训练数据里学到的。
任务是真实的:修 bug、加功能、做重构,就是他们平时会做的事。每个任务平均耗时两小时。随机分配是否可以用 AI——允许的那组主要用 Cursor Pro,底层是 Claude 3.5 和 3.7 Sonnet,当时的前沿模型。
实验开始前,开发者自己预测:AI 应该能让我快 24%。实验结束后,他们仍然相信 AI 让他们快了 20%。
实际结果是慢了 19%。
这不是 AI 能力的问题。同类前沿模型在 SWE-bench Verified 等基准测试上普遍表现亮眼——那些任务是从开源 PR 中提取的、有自动化测试的、边界清晰的编程问题。但 METR 的任务不是那样的。它们是散落在百万行代码库里的真实 issue:有时候是你得先花二十分钟理解业务逻辑才能下手的那种;有时候改一个地方要同时改三个模块的测试才能通过的那种;有时候代码逻辑本身没问题,但你不小心引入的副作用会在二十个文件之外爆炸的那种。
METR 团队分析了 20 个可能的解释因素,排除了大部分实验人为问题——开发者不是新手、他们确实按照随机分配使用了或没使用 AI、任务难度在两组之间是均衡的、PR 质量标准也没有因为分组不同而下降。剩下的 5 个可能解释里,最核心的几个指向了同一个方向:
隐式要求和隐性上下文。 高质量的开源项目有严格的编码风格、测试覆盖率要求、文档要求和 linting 规则。这些约束不是在 issue 描述里写的——它们是沉淀在这个仓库的惯例里的,是五年来形成的不成文规则。人类开发者已经内化了这些规则,AI 看不到它们。它生成的代码能通过功能测试,但不符合这个仓库的写法。开发者不得不花额外的时间让 AI 的产出「收敛」到项目标准——改命名、调结构、补测试、修 lint——这些时间加起来,超过了自己写的时间。
这恰好对应了第 1 篇里那个注册页面的故事:Agent 完美实现了它理解的任务,但它理解的任务里不包含「密码要 bcrypt」「错误提示不能泄露其他用户」「不要附带任何关联账户信息」——因为那些约束没有写在任何 AI 能读到的地方。
不同的是,在 Copilot 实验里,任务是「实现一个 HTTP server」——不存在隐式约束,所有规则都在 HTTP 协议里写死了。在 METR 实验里,任务是「修一个 pandas 的 bug」——隐式约束多到任何一份 issue 描述都不可能写全。
DORA 2025 报告从另一个角度看到了同一件事。大规模调查数据显示:AI adoption 每提高 25%,交付吞吐量下降 1.5%,交付稳定性下降 7.2%。根因分析指向同一个机制——AI 让代码产出速度暴增,但 batch size 也大了,review 来不及消化,测试覆盖跟不上。结果不是变快了,是变乱了。

同一个公式:AI 的速度增益 = 任务的结构化程度