
本文是「AI 时代的编码新范式」系列的第 1 篇。全系列共 9 篇,基于 43 篇行业文献、学术论文与一线实践报告,探讨 Spec-Driven Development 如何在 AI Agent 时代从边缘实践变为工程的基础设施。每篇可独立阅读。
你对 Claude Code 说了一句话。十五分钟后,一个注册页面跑起来了。
表单能提交。校验有提示。UI 干净整洁。
你正准备开香槟,低头看一眼那个黄色的警告框——
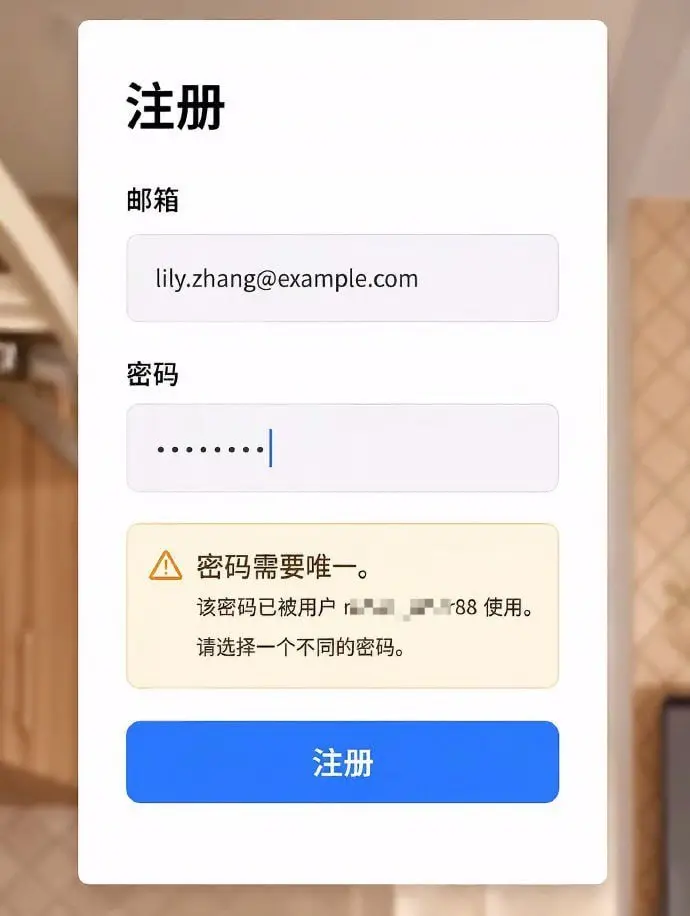
在于你脑子里想的“注册页面”和 Agent 理解的“注册页面”,根本不是同一个东西。你没告
区分“用户不存在”和“密码错误”。你没告诉它永远不要在 UI 上暴露另一个用户的任何信息。
你省下了一小时的需求描述时间。你用三个小时来找遍代码里所有这类 bug,再一个一个修掉。
这不是 bug。这是 vibe coding 在 2026 年的本来面目。
口喷需求:描述 ≠ 定义

地按 Tab。
两年过去了,vibe coding 升级了。你不再需要狂按 Tab——你只需要打开 Claude Code 或 Codex,对着终端说一句话。Agent 替你分析代码库、生成实现、跑测试、提 PR。你甚至不需要知道它具体写了什么。这是 Andreessen Horowitz 最近描述为“从 keyboard-first 到 intent-first”的转变:你表达意图,Agent 替你执行。
但这里有一个根本性的混淆:描述你想做什么,和定义你该做什么,是两件完全不同的事。
OpenAI 在 A Practical Guide to Building Agents 中对 Agent 的定义是“能独立代替你完成整个流程的系统”。问题恰恰出在“独立”这两个字上:Agent 独立了,但它的判断基准还是你输入那句话时隐含在脑中的所有假设——那些你没说出口、Agent 也猜不到的假设。
你以为你说了“注册页面”。Agent 以为你说的是“一个能接收邮箱和密码、验证格式、提示错误、完成注册的表单页面”。
它完美地实现了它理解的版本。它只是不知道——你也没告诉它——密码不能明文对比、错误提示不能区分用户、邮箱不能暴露给其他用户的 session。
DeepLearning. AI 在它的 SDD 课程里说得直白:“Vibe coding is fast, but it often produces code that doesn‘t match what you asked for. Spec-driven development is the disciplined alternative.”不是 Agent 不够聪明。是自然语言本身就不是精确接口。
模糊性不是漏洞,是自然语言的默认状态

每一种自然语言都建立在共享上下文的基础上。当两个人对话时,他们在调用几十年共同生活在这个世界上的经验来填充对方没说出口的部分。你说“去吃饭”,对方知道你不是去吃早餐。你说“把灯关一下”,对方知道你指的是这间屋子最亮的那盏灯。共享上下文越深厚,语言越简洁。
你跟 Agent 之间没有共享上下文。
当你说“帮我做一个注册页面”,Agent 唯一能参考的是它训练数据里成千上万个“注册页面”的平均模样。那个平均值里有邮箱输入框、密码框、重复密码框、注册按钮——但是没有“不要暴露其他用户的密码”这条规则。因为训练数据里的大多数注册页面也不考虑这个——它们只是在演示 UI,不是在实现真正的安全系统。
这不是 Agent 的漏洞。这是自然语言的系统属性:每说一句话,你都省略了无数细节。跟人类对话时,那些细节由你们的共同经验自动补全。跟 Agent 对话时,那些细节由 Agent 的训练数据平均值自动补全——但那个平均值不是你的经验,也不是你的项目标准。
你省下的需求澄清时间不是消失了。它们被推迟了。推迟到了代码跑起来之后。
当你回过头修 bug、补安全漏洞、改“看起来没问题但逻辑完全不对”的业务规则时,你正在用 debug 的时间偿还你在 prompt 里省下的需求描述时间。debug 的代价比需求描述高得多——不仅因为你要翻代码、定位问题、验证修复,更因为你已经在错误的方向上建了一些东西,那些东西会成为未来方向性返工的沉没成本。
一种更精确的表述:你是把“理解成本”从 Agent 启动前转移到了 Agent 产出后。后者的单价远高于前者。
一个反直觉的对比:慢在开头,快在全程
回到那个注册页面的案例。如果接到这个任务时,你先花十五分钟,把自己踩过的坑、学到的教训、项目里约定俗成的规则——那些本来只存在于你脑子和团队 Slack 聊天记录里的东西——沉淀成一份结构化的说明。你可以自己写,也可以对着 Claude Code 说「帮我整理一份注册功能的安全约束和验收标准」,然后 review 它输出的内容,把你不同意的改掉、把你漏掉补上。写完之后,你得到的是这样一份东西——
注册功能 Spec
概述:为平台提供邮箱注册入口。用户通过邮箱 + 密码创建账号,注册成功后跳转至登录页。本期仅做邮箱注册,后续版本考虑社交登录和邮箱验证。
用户流程:访问
/register→ 填写邮箱 + 密码 + 确认密码 → 前端校验格式 →POST /api/auth/register→ 后端校验 → 写入数据库 → 返回成功,前端跳转登录页。数据字段
password:字符串,必填,最小长度 8 位(产品决策:不做大小写/特殊字符复杂度要求,降低注册摩擦)
created_at:自动生成安全要求
密码使用 bcrypt 存储,cost factor ≥ 10,不可逆
错误提示不做过度模糊化:区分「该邮箱已注册」和「密码长度不足」——这两种情况用户可以修正,不需要藏起来。但不附带任何关联账户信息(如注册时间、上次 IP 等字段不暴露)
接口响应中不返回其他用户的数据,即便是脱敏后的也不返回
接口
POST /api/auth/register,请求体{ email, password }成功 → 201,body
{ message: “注册成功” }失败 → 400(校验失败)或 409(邮箱冲突),body
{ error: string },仅含用户可操作的提示边缘情况
空字段 → 400,指明哪些字段必填
密码前后空格 → 自动 trim
重复提交(竞态)→ 数据库唯一索引兜底
明确不做(本期)
不发送验证邮件
不做社交登录(Google / GitHub / 微信)
不做 CAPTCHA / 注册频率限制(先上线,后续加日志监控滥用量)
验收标准
新邮箱 + 合规密码 → 201,数据库密码字段为 bcrypt 哈希
已注册邮箱 → 409,提示「该邮箱已注册」
密码 < 8 位 → 400,提示密码长度不足
非法邮箱格式 → 400,提示邮箱格式不正确
任一必填字段为空 → 400
接口响应中不出现其他用户的标识信息

这十五分钟感觉“慢”了。你没在写代码,你在写一份看起来像需求的文档。十五分钟过去了,你一行功能代码都没写出来。
但 Agent 读完这份 spec 之后——它一次就做对了。它不会在密码对比上走捷径,不会在错误提示上过度友好,不会在响应里附带“哦对了你隔壁用户的密码跟你一样要不要换一个”。因为你把这些约束写进了 spec。
而在没有 spec 的场景里,你七秒钟打完那行 prompt,Agent 开始吭哧吭哧干活——你省下的那十四分五十三秒,会在接下来的三天里变成:定位“password uniqueness”提示泄露了其他用户密码 ≈ 30 分钟、排查为什么密码存储是明文 ≈ 1 小时、重构错误提示逻辑 ≈ 2 小时、写安全补丁 + 测试 ≈ 半天、给你的技术 Leader 解释“为什么上次 code review 没发现问题”:不可估量。
七秒钟省下的时间,用三天来还。