
📌 本文是「AI 时代的编码新范式」系列的第 4 篇。全系列共 9 篇,基于 43 篇行业文献、学术论文与一线实践报告,探讨 Spec-Driven Development 如何在 AI Agent 时代从边缘实践变为工程的基础设施。每篇可独立阅读。第 3 篇用数据证明了「AI 快不快取决于任务有多结构化」;本篇讲的是:让任务变得结构化之后,还有一个更底层的问题没解决——Agent 根本记不住上一轮发生了什么。
你已经让 Agent 跑了两个小时。上下文窗口快满了,响应越来越慢,你不得不重启会话。
重启后,你对 Agent 说「继续」。
Agent 沉默了几秒,然后开始重新理解项目。它重新读了目录结构。它重新翻了最近几个文件的 git log。它尝试推断「上一轮做到哪了」——但推理基于的是代码的当前状态,不是刚才那一小时的决策过程。有些判断它猜对了,有些它完全搞错了方向。它花了二十分钟重新走了一遍你已经走过的路,然后才勉强接上。
你不是在跟一个助手合作。你是在跟一个每次见面都要重新自我介绍的人合作。
这是 Agent 编码最被低估的问题。不是模型不够聪明——Claude Opus 4.8 和 GPT-5 已经聪明到能独立完成小时级任务了。不是上下文窗口不够大——200K token 够装下一整本小说了。是架构问题:Agent 没有长期记忆。 每一次会话重启,对它来说就是世界重置。
而文档,恰好是解决这个问题的唯一手段。

被忽略的架构赤字
「Agent 没有长期记忆」这句话听起来像是一个已知的局限性,但它的工程后果远比大多数人意识到的严重。
人类工程师切换任务时,脑子里带着几十样东西。他知道昨天修的那个 bug 改动了三个文件,知道重构进行到一半卡在了测试用例上,知道上次开会讨论决定暂缓某个功能的实现但保留接口预留。他不需要重新翻阅整本代码库来找回这些上下文——它们在他的记忆里,随时可用。
Agent 不是这样的。
Agent 每次新会话启动时,手里只有三样东西:系统提示词、项目根目录下的配置文件(如果写了的话),以及它能读取到的文件内容。昨天下班前它花了四十分钟才搞清楚的那个架构决策?不在任何文件里。两小时前它发现用方案 A 会破坏模块 B 的兼容性所以改用方案 C?除非有人在当时把它写进了文档,否则这条推理链彻底消失了。
Anthropic 的工程团队在开发长程 Agent harness 时,用了一个精确的类比来描述这个问题:「想象一个软件项目由轮班工程师负责,每个新工程师到达时对上一班的任何事都没有记忆。」不是「记不太清」——是零记忆。每一班都从零开始。
这或许也能解释 METR 实验里那些经验丰富的开发者在用 AI 时反而慢了 19%:那些「隐式上下文」不仅包括代码风格和 linting 惯例——还可能包括 Agent 自己在几分钟前刚刚形成的理解。当 Agent 的短期推理无法持久化时,每一次上下文窗口刷新都是一次潜在的理解丧失。人类开发者可以凭记忆跨会话推进任务;Agent 不能。
这个问题有解吗?Anthropic 的答案是:把 Agent 的每一次思考都写进文件里。 不是「写一份详细的需求文档」那种写——是让 Agent 自己写。把文档变成 Agent 的外部硬盘。

Anthropic 的 harness:把文档变成 Agent 的记忆层
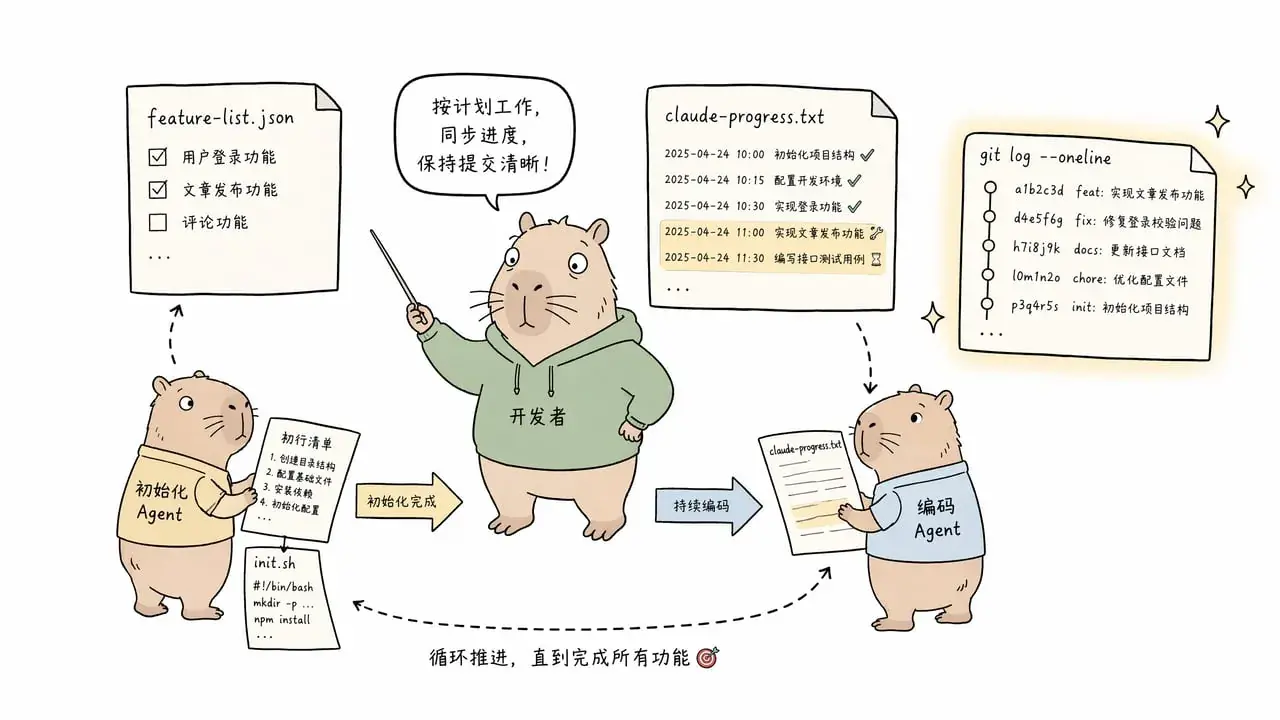
2025 年末,Anthropic 的工程团队公开了一套长程 Agent 的实践方案,核心思路出奇地简单:用两个 Agent、三份文件,搭出一个跨会话的记忆系统。
第一步:初始化 Agent。 接到一个高层次的任务——比如「做一个 claude.ai 的克隆版」——第一件事不是写代码,是让一个专门的初始化 Agent 搭建整个环境。它做了三件事:把用户的高层意图扩展成一份详细的功能清单(claude.ai 克隆版被拆成了超过 200 条端到端功能描述——「用户可以打开新聊天」「用户可以输入查询」「用户按回车后看到 AI 回复」),每一条都标记为「未通过」;写一个 init.sh 脚本,让后续任何 Agent 都能一键启动开发服务器;做一次初始 git commit,为后续的增量提交建立一个清晰的起点。
第二步:编码 Agent。 初始化完成后,每一次新会话启动一个编码 Agent。这个 Agent 启动时做的第一件事不是写代码,是阅读。它读 claude-progress.txt 了解上一轮做到了哪。它读 git log 了解最近的改动。它读功能清单文件,挑一条还没通过的功能,开始干活。做完之后,它写 git commit,更新进度文件,然后结束会话——把环境留给下一个 Agent。
这里的核心设计原则是:每一个 Agent 离开时,代码库必须处于一个「干净」的状态。 没有半成品。没有未记录的决策。没有「我也不知道这段代码是干嘛的但没它就会崩」的神秘补丁。每一次会话结束时,代码库的状态应该可以直接合并到主分支——不是因为每次产出都完美,是因为每次产出都是完整、可理解、可继续的状态。
这套流程解决了长程 Agent 的四个经典失败模式:
-
一步到位综合征:Agent 试图一次性实现所有功能,上下文窗口中途爆掉,留下半实现的特性。解法:功能清单文件把大目标拆成小步骤,每次只做一个。
-
过早宣布胜利:Agent 看到代码库里有进展就认为任务完成了。解法:功能清单里每一条都标记了通过/未通过状态,Agent 只有把所有条目都改成了「通过」才算完。
-
自欺欺人的测试:Agent 改了代码、跑了单元测试、就标记为完成——但端到端根本不 work。解法:显式要求 Agent 用浏览器自动化工具像真实用户一样操作一遍,截图验证。
-
启动时的方向迷失:每个新 Agent 都要花大量时间猜「现在是什么情况」。解法:三行标准启动步骤——
pwd确认工作目录 → 读 git log 和进度文件 → 从功能清单里选下一个任务。
当这套机制跑起来之后,一个典型 Agent 会话的启动消息看起来是这样的:先执行 pwd,确认自己在正确的目录里;然后读 claude-progress.txt,看上一轮做了什么、卡在哪里;然后跑 init.sh 启动开发服务器,用浏览器自动化跑一遍基础端到端测试确认 app 还活着;然后打开功能清单文件,选最高优先级、还没通过的那一条,开始干活。
三份文件撑起了这整个过程:功能清单(What)→ 进度文件(Where)→ git log(Right?)。三层各司其职。Agent 不靠「记住」来推进——它靠「读」来推进。
这不是 Anthropic 独有的——这是 Agent 编码的生存本能
Anthropic 的 harness 方案看起来像是为超长任务设计的特殊工具。但实际上,任何让 Agent 工作超过一个会话的开发者都会自发地走向同样的模式。