📌 本文是「AI 时代的编码新范式」系列的第 2 篇。第 1 篇讲了「口喷需求的代价」——Agent 猜不对你脑子里没说的约束。本篇讲的是:那些约束写下来之后,到底发生了什么变化——不是多了一份文件,而是文档在整个工程流程中的身份变了。每篇可独立阅读。
两行命令。同一个意图。
# 盲飞——Agent 不知道你想干什么
claude "帮我重构这个 auth 模块"
# 航图——Agent 有一份明确的执行契约
# (示意,非 Claude Code 真实 CLI 语法)
claude --spec specs/refactor-auth.md
第一行让 Agent 盲飞。第二行给了它航图。

这中间的差距,不是你多写了一篇文档,而是一份 spec 的身份发生了三重转变——从给人看的说明书变成给 Agent 读的执行协议、从写完就过时的静态文件变成每次会话都重新加载的 living document、从人类阅读的散文变成机器解析的接口配置。
这三重转变加起来,等于一件事:在 AI Agent 成为你的主力编码者的时代,spec 不再是「开发过程中顺便产出的一份文件」。spec 是开发过程的第一道输入。
第一重转变:从说明书到执行协议
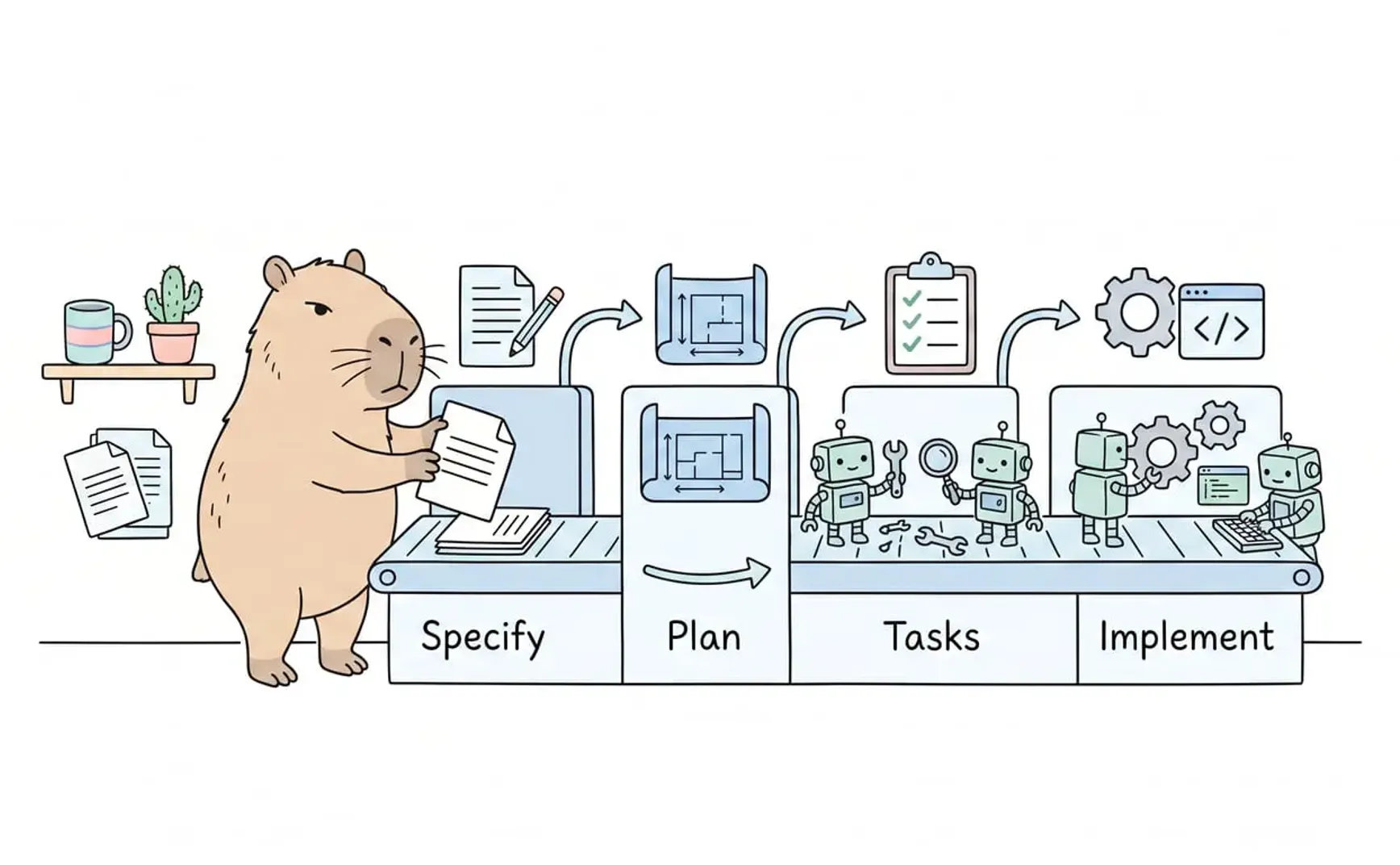
2025 年 9 月,GitHub 开源了 Spec Kit——一个专门面向 AI 编码 Agent 的工具包。它把开发流程重新组织成四个阶段:Specify → Plan → Tasks → Implement。
这看起来像是一个普通的流程重组。但它做了一件关键的事:把 spec 从「开发开始前要做完的事」变成了「开发本身的第一步」。
在传统流程里,写需求文档和写代码是两个阶段——由不同的人、在不同的时间、用不同的工具完成。交接点是一封邮件或一个 Jira ticket。文档一旦交出去,就和实现过程解耦了。代码可能在三个月后偏离 spec,但 spec 不会知道——它会安静地躺在 Confluence 里过期。
在 Spec Kit 的四阶段模型里,Specify 不是前置步骤。它就是管线本身的第一道工序。spec 写完之后直接流入 Plan(Agent 读取 spec 生成执行计划),Plan 流入 Tasks(拆解为可执行的子任务),Tasks 流入 Implement(Agent 逐项编码)。spec 是输入信号,代码是输出信号。中间没有人类翻译环节,没有「你把需求写成邮件、他把邮件理解成代码」的损耗。
Microsoft 把这套方法称为 spec-first——不仅是「先写 spec 再写代码」,而是 spec 驱动代码生成。他们的核心理念是:spec 应当作为业务意图与代码/测试之间的 shared source of truth。这是一句很容易被忽略的话,但它暗含了一个巨大的立场转变:source of truth 不再是代码,而是 spec。代码只是 spec 的一种表达形式。
GitHub Spec Kit 目前已支持 30+ AI 编程 Agent 的集成【^1】——Claude Code、Copilot、Codex、Cursor 都在列表里。这意味着同一份 spec 可以被不同的 Agent 读取和执行。spec 不再绑定到某一个工具、某一个 IDE、某一个团队的工作流程。它变成了一个跨 Agent 的执行协议,就像 REST API 不关心 consumer 是用 curl 还是用 Postman——spec 只定义「做什么」「怎么做」「做对的标准是什么」,谁来实现都可以。
Thoughtworks 在 2025 年的一篇行业分析中这样描述 SDD 的核心逻辑:用写好需求规范来驱动 AI Agent,本质上是用结构化自然语言替代模糊 prompt。这个定义本身就在说:spec 已经不再是文档了。它是 prompt。是给机器的指令。
第二重转变:从静态文档到 Living Document
传统的需求文档有一个半衰期。写完的那一刻就开始过期。Sprint 2 的需求调整不会自动回写到 Sprint 1 的 PRD 里。三个月后,文档和代码之间的关系已经无法信任——你不知道是文档没更新,还是代码写偏了。
但在 Agent 工作的方式里,这个关系被翻转了。