

系列最后一篇。前四篇从概念框架到工程实践搭了一条完整的线,这篇把线头接到学术前沿。三篇 arXiv 论文,分别从「全景地图」「自动进化」「架构实证」三个角度切进来,读完你会发现很多我们前面讨论的结论,学术界已经在用更系统的方法验证了。
这个系列一路写下来,有一条暗线:我们一直在从工程实践里归纳模式——Harness 的四个维度、Loop 的三个齿轮、三层心智模型。这些归纳对不对、全不全,需要学术界的系统研究来校正。
我是怎么找到这三篇的
说实话,不是一开始就有明确目标的。第四篇写完 Claude Code 和 Stripe Minions 的拆解之后,有件事让我不太踏实:我们归纳的框架(Harness 四个维度、Loop 三个齿轮)是基于两个系统的深度拆解推出来的,样本太小。我需要一个外部校准——学术界有没有人用更系统的方法做过类似的事?如果有,他们的分类体系和我们的对得上吗?对不上的地方差在哪?
于是我在 arXiv 上做了几轮检索,关键词大概是这样演变的:
-
先用
agent harness architecture搜,出来一堆不相关的,大部分是 robotics 和 embodied AI 里的 “harness”(物理意义的安全带/线束)。 -
加上
LLM限定,搜LLM agent harness architecture survey,找到了 2605.18747(Code as Agent Harness)。这篇是综述,参考文献有几百篇,顺着它的引文往回翻,发现了 2604.18071(Architectural Design Decisions)和 2604.25850(Agentic Harness Engineering)。 -
三篇放在一起看,时间上都在 2026 年 4-5 月,主题高度相关但切入角度完全互补——一篇画地图、一篇造引擎、一篇读代码。
这个发现本身就是一个自学的经验:不要指望一次搜索就找到所有好东西。找到一篇高质量的综述之后,顺着它的引文网络往回挖,比重新搜索高效得多。
刚好,2026 年上半年 arXiv 上出现了这三篇直接相关的论文,一篇比一篇有意思。它们不是彼此独立的——放在一起读,能看出一条从「描述现状」到「自动进化」到「实证验证」的递进线索。
第一篇:Code as Agent Harness(2605.18747)——给整个领域画一张地图
论文全称:Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems
作者阵容:40+ 位作者,涉及多个机构。2026 年 5 月 18 日提交。
这是一篇大型综述,野心很大:它提出了一个统一视角——代码不只是 Agent 的产出物,而是 Agent 的基础设施本身。在这个视角下,代码充当了 Agent 推理的基底、行动的媒介、环境的建模工具,以及执行验证的手段。
论文把整个领域组织成了三个层层递进的维度:
Harness Interface(接口层)。 代码如何连接 Agent 到推理、行动和环境建模。这基本上对应我们在前四篇里讨论的「工具集成」——但论文的视角更宽,不仅包括传统的 function calling 和 MCP 工具,还包括 Agent 通过代码来理解和建模它所处的环境。
Harness Mechanisms(机制层)。 规划(planning)、记忆(memory)、工具使用(tool use)——支撑长时间执行的核心机制,加上反馈驱动的控制和优化让 Harness 变得可靠和可自适应。这层同时覆盖了我们说的 Harness 的「上下文管理」和 Loop 的「验证反馈」——论文没有像我们那样把 Harness 和 Loop 分成两层,而是把执行机制统一放在 Harness 的概念下讨论。
Scaling the Harness(扩展层)。 从单 Agent 到多 Agent——共享代码构件如何支撑多 Agent 的协调、审查和验证。这对应了我们讨论的「多 Agent 协调」和 Claude Code 的 subagent 树模式。
论文覆盖的应用场景非常广:编程助手、GUI/OS 自动化、具身 Agent、科学发现、个性化推荐、DevOps、企业工作流——几乎把当前 Agent 落地的所有方向都扫了一遍。
但对我来说最有价值的部分不是它的分类体系,而是它列出的开放挑战。这几个问题,每一个都值得未来深入:
-
超越最终任务成功的评估:现在的评估只看任务做没做完,不看过程质量。Agent 用了多少 token、绕了多少弯路、产出的代码能不能维护——这些都没有系统化的评估标准。
-
不完整反馈下的验证:不是每次运行都有完整测试覆盖,Agent 怎么在没有充分验证信号的情况下判断自己做对了?
-
无回归的 Harness 改进:改了 Harness 的某个部分,怎么保证不会把别的地方搞坏?
-
多 Agent 间的一致共享状态:多个 Agent 并行工作,状态怎么同步、冲突怎么解决?
-
安全关键操作的人类监督:什么操作必须经过人类?这个边界怎么动态调整?
这些问题读起来特别亲切——因为我们在前四篇的讨论里或多或少都碰到了。综述的价值就是把散落的问题系统化了。
自学备忘:这篇论文附带了一个持续更新的 GitHub 仓库 Awesome-Code-as-Agent-Harness-Papers,按接口、机制、扩展三层分类整理了相关论文。如果你读完这篇想深入某个子方向,从这个列表开始比重新搜索效率高得多。我自己的方法是:先通读综述理解全局地图,然后从列表里挑 3-5 篇跟自己最相关的精读,这样既有全景视角又不至于在文献海里迷路。
第二篇:Agentic Harness Engineering(2604.25850)——让 Harness 自己进化
论文全称:Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
这篇是我三篇里最喜欢的。如果说第一篇是地图,这篇就是引擎——它不满足于描述 Harness,而是提出了一个让 Harness 自己改进自己的闭环系统。
核心问题:Harness Engineering 目前还是手工活——工程师凭经验调工具配置、改 system prompt、调整 context 策略。自动化面临三个障碍:Harness 的可编辑组件太杂(action space 不统一)、原始运行轨迹太长(信息淹没在 token 海里)、改了之后效果难归因(不知道是哪个改动起了作用)。
在读这篇之前,我对 “Harness 能不能自动化” 这个问题其实是半信半疑的。直觉上觉得可以,但不知道怎么系统化地做——因为每次改 prompt 或调工具配置的时候,确实像是在碰运气。这篇论文让我一下子想明白的是:问题不在自动化本身,而在于你没有给自动化提供足够的信息。三个障碍本质上都是信息不够——不知道改了哪个组件、不知道历史轨迹里藏了什么信号、不知道改完之后效果到底怎么归因。可观测性就是给这三个信息缺口分别打上补丁。
解决方案:AHE(Agentic Harness Engineering)提出了三个「可观测性支柱」来应对三个障碍——
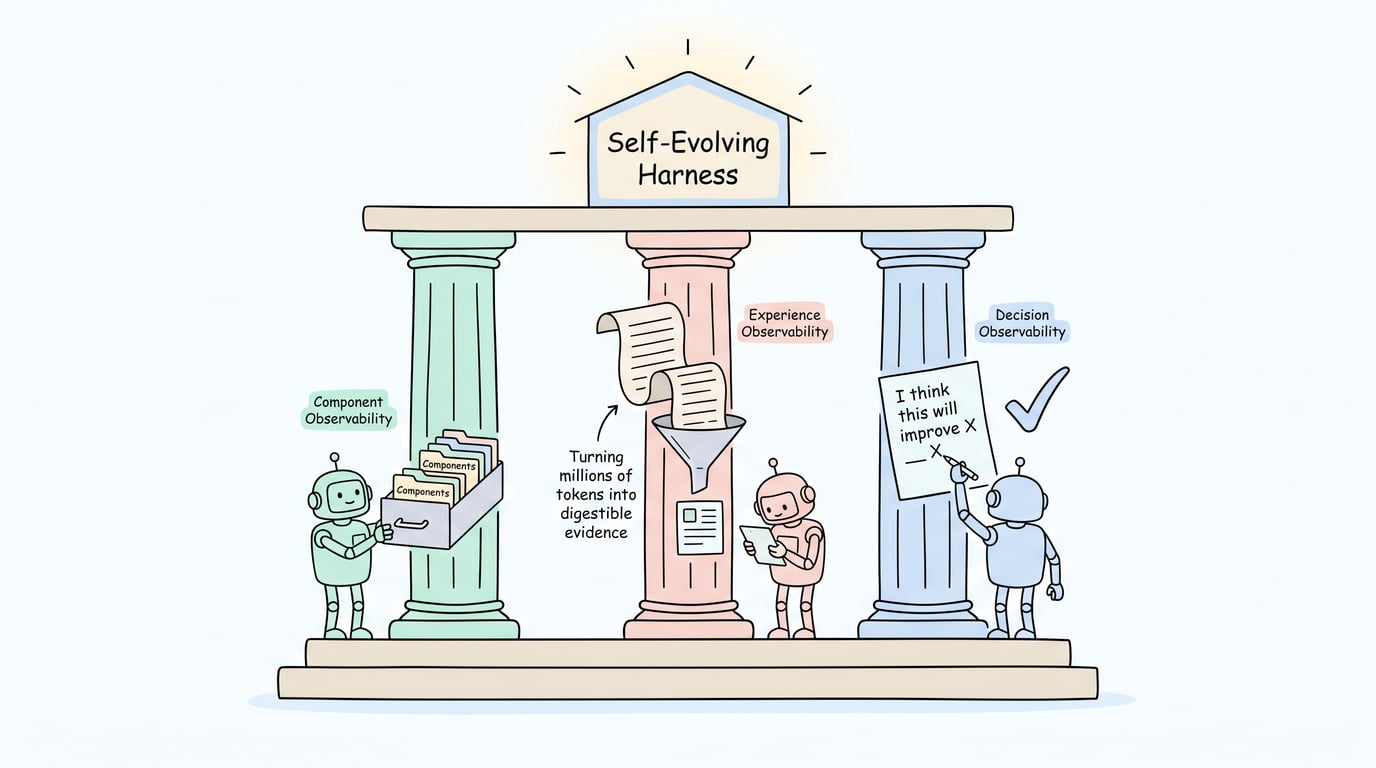
-
Component Observability(组件可观测性):给每个可编辑的 Harness 组件一个文件级表示,让 action space 变得显式且可回滚。说白了就是 Harness 的每个部分都能被独立地改、独立地测。
-
Experience Observability(经验可观测性):把数百万 token 的原始运行轨迹蒸馏成分层的、可钻取的证据语料。Agent 不用读所有东西,而是读经过提炼的「经验报告」。
-
Decision Observability(决策可观测性):每次编辑都附带一个「自声明预测」——「我改这个是因为我认为它会改善 X」,下一轮跑完之后用实际结果验证这个预测对不对。这让每一次改动都变成了一个可证伪的契约。
这三根支柱合在一起,核心思想是:把每一次 Harness 编辑变成一个可验证的实验,而不是一个碰运气的猜测。
实验结果:10 轮 AHE 迭代之后,在 Terminal-Bench 2 上 pass @1 从 69.7% 提升到了 77.0%——超过了人类设计的 Codex-CLI harness(71.9%)和两个自进化基线 ACE(Autonomous Code Evolution)和 TF-GRPO(Training-Free Group Relative Policy Optimization)。这里有个细节值得注意:AHE 的 Evolve Agent、Analyzer Agent 和 Target Agent 三个角色共享同一个基座模型,这意味着性能提升完全来自 Harness 层面的改进,而不是换了更强的模型。
更关键的是,进化后的 Harness 不用重新进化就能迁移——在 SWE-bench-verified 上用比原始版本少 12% 的 token 达到了更高的总体成功率,跨三个不同模型族都获得了一致的提升(+5.1 到 +10.1 个百分点)。这说明什么?Harness 里积累的不是对某个 benchmark 的过拟合,而是可迁移的工程经验。
代码已开源:GitHub - agentic-harness-engineering。如果你想复现或者在自己的 Agent 系统上跑 AHE,这是目前最直接的起点。
最有意思的发现:消融实验表明,改进集中在工具、中间件和长期记忆上,而不是 system prompt。这意味着 Harness 的「硬结构」(工具怎么接、中间件怎么写、记忆怎么管)可以在任务之间迁移,而「软策略」(prompt 怎么写)的迁移效果差得多。这跟我们系列里反复说的「工程重于指令」完全对上了。
这个消融结果我读了好几遍才消化。它的分量在于:它不是一个观点,而是一个实验证据。在这之前,“工程结构比 prompt 重要” 只是我自己的判断和直觉。但 AHE 告诉你:让 Harness 自动进化 10 轮之后,拆开看是哪些组件在起作用——工具、中间件、长期记忆贡献了大部分提升,system prompt 的贡献几乎可以忽略。这就是把直觉变成了可复现的结果。以后跟别人讨论 Agent 系统设计的时候,不用再说“我觉得工程更重要”,可以直接说“AHE 的消融实验表明,结构是可以跨任务迁移的,prompt 不行”。
第三篇:Architectural Design Decisions(2604.18071)——70 个系统的实证扫描
论文全称:Architectural Design Decisions in AI Agent Harnesses
作者:Hu Wei(独立作者)。2026 年 4 月 20 日提交。全文 35 页、13 张表。
这篇的风格和前两篇完全不同——它不做综述也不提新方法,而是做了一件事:读代码。作者系统地分析了 70 个公开可用的 Agent 系统项目,从源码和技术文档里提取架构设计决策,然后用实证方法找规律。
独立作者这件事值得单独提一下。在这个领域,40+ 作者的大型综述和 10+ 作者的实验论文越来越常见,一个人啃完 70 个项目的源码还提炼出系统性的规律,对自学者的参考价值在于它证明了:不需要大团队,靠方法和耐心也能做出有分量的实证研究。你只需要一个清晰的研究问题、一套可重复的分析协议,以及愿意坐下来一行一行读代码的耐心。
五个反复出现的架构维度:
-
Subagent Architecture(子 Agent 架构):系统怎么拆任务、怎么委托子 Agent
-
Context Management(上下文管理):状态怎么存、怎么检索、怎么跨任务传递
-
Tool Systems(工具系统):工具怎么注册、怎么发现、怎么调用
-
Safety Mechanisms(安全机制):权限控制、操作审计、沙箱隔离
-
Orchestration(编排):多 Agent 怎么协调、工作流怎么定义
这五个维度跟我们自己归纳的 Harness 四个维度 + Loop 三个齿轮的交叉很有意思——论文没有区分 Harness 和 Loop,而是把所有 Agent 基础设施统一放在「架构设计决策」的框架下。这说明学术界和工程界在对「Agent 基础设施由哪些部分组成」这个问题上,正在收敛到相近的答案。
几个有信息量的发现:
-
上下文管理策略上,文件持久化(file-persistent)、混合(hybrid)、层级化(hierarchical)是主流,跟 Claude Code 的 CLAUDE.md + compaction pipeline 设计一致。
-
工具系统仍以注册表模式(registry-oriented)为主,但 MCP 和插件导向的扩展正在兴起——Stripe 的 Toolshed(MCP-based)和 Claude Code 的 MCP 集成都是这个趋势的注脚。
-
安全机制上,中级隔离很常见,但高保证审计(high-assurance audit)罕见——这个发现和我们在第四篇的观察一致:大多数系统还停留在「加个沙箱」的阶段,像 Stripe Minions 那样「隔离即权限」的深度架构设计并不多。
-
协调整合越深,上下文服务越显式;执行环境越强,治理结构越结构化;工具注册边界越正式,生态野心越大——这些共现模式揭示了架构决策之间的系统性关联。
论文最后归纳了五种典型的架构模式:轻量工具型、均衡 CLI 框架型、多 Agent 编排型、企业系统型、场景垂直型。Claude Code 大致落在均衡 CLI 框架型,Stripe Minions 落在企业系统型。
自学笔记:这篇论文的方法论本身就是一个很好的自学模板。它的三个研究问题——「哪些维度反复出现」「哪些决策倾向于一起出现」「总体上有哪几类典型模式」——其实可以直接套用到任何你感兴趣的软件工程领域。下次你想系统性地理解一个技术领域(比如 MCP 工具生态、Agent 安全框架、或者任何你刚接触的方向),可以试试这个三步法:先收集 20-30 个代表性项目的源码和文档,然后提取它们的设计决策,最后找共现模式和典型分类。不需要 70 个,20-30 个就够看出规律了。
三篇论文和这个系列的关系
回头翻一下前四篇,我发现我们自己做了一件和这 2604.18071 那篇论文类似的事——从具体系统里提取模式。区别在于他们是系统地读了 70 个项目的源码,我们是拆了两个(Claude Code 和 Stripe Minions)然后推演通用框架。方法不同,但很多结论撞在了一起。
Harness 的四个维度(工具、安全、上下文、生命周期)和论文的五个架构维度(子 Agent、上下文、工具、安全、编排)有高度重叠——我们把「编排」拆成了 Harness 的「生命周期」和 Loop 的「任务分解」,论文把编排独立成一个维度。这更多是切分方式的不同,不是实质分歧。
而 AHE(2604.25850)那篇论文提出的「Harness 自动进化」闭环,直接回答了我在写这个系列时一直悬在心里的一个问题:好的 Harness 设计能不能自动化? 目前的答案是「可以,但需要在可观测性上做大量工程投入」。三根可观测性支柱(component、experience、decision)本质上是把 Harness Engineering 从一个「手工艺」变成一个「可优化的系统」——这个方向我觉得会是 2026 年下半年到 2027 年的核心研究热点。
Code as Agent Harness(2605.18747)列出的开放挑战里,我觉得最紧迫的一条是「超越最终任务成功的评估」。前四篇我们讨论 Harness 和 Loop 怎么设计,但怎么评估它们好不好——不是看「任务做没做完」,而是看「做得漂不漂亮」——这个方法论目前几乎是空白。AHE 论文里 decision observability 的「每次改动附带预测 + 后续验证」机制,可能是一个起点。
写在系列最后
五篇写下来,从「Harness 和 Loop 到底是什么」,到拆开四个维度、拆开三个齿轮,到拿两个真实系统练手,到接上学术前沿——这条线走完,我觉得最有价值的不是记住了多少定义,而是脑子里有了一个三层结构:看到任何一个 Agent 系统,能自动地把它拆成模型层、Harness 层、Loop 层,然后每一层用自己的四个维度(或三个齿轮)去理解它为什么这样设计。
读完三篇论文之后,我修正了几个想法
论文不只是一个外部验证,它逼着你重新审视自己的框架。读完三篇之后,我有几个想法发生了变化:
第一,Harness 和 Loop 的分界可能没有我想象的那么清晰。 我们自己在第二篇和第三篇里把 Harness(操作系统)和 Loop(认知循环)分成了两层,但三篇论文都没有做这个区分——2605.18747 把“机制”(planning, memory, tool use)统一放在 Harness 的概念下讨论;2604.18071 的五个维度里,“编排”是一个独立维度,既包含我们的“生命周期管理”也包含“任务分解”。这说明学术界的主流视角是把 Agent 基础设施看成一个整体,而不是分成 Harness 和 Loop 两个层面。这个切分是我自己的框架偏好,不一定错,但要知道它不是唯一的切法。
第二,“工程重于指令”不再只是一个直觉。 AHE 的消融实验给了一个很硬的证据:自动进化 10 轮之后,工具、中间件和长期记忆贡献了大部分提升,system prompt 几乎没有贡献。以后跟别人讨论这个观点的时候,可以直接引用这个实验,不需要再解释半天。
第三,自学的方法可能比自学的结论更值得保留。 我们这个系列的方法——拆两个系统、归纳维度、推演框架——和 2604.18071 的方法在底层是同构的:从具体案例里提取模式。区别在于他们做了 70 个、有严格的分析协议,我们做了 2 个、靠的是深度追问。这两条路不是互斥的——先做几个深度案例建立直觉,再用大规模实证扫描去验证和修正,是最扎实的自学路径。
接下来往哪挖
这个系列是一个开始,不是一个结束。论文列出的开放挑战、AHE 的自动进化方向、Addy Osmani 的六原语框架——每一条线都能往下挖。但框架建好了,再往里填新东西就不会迷路。
如果你要从零开始深入这个方向,我建议的顺序是:
-
先读 2605.18747 建立全局地图(打开 arXiv 页面,读 intro 和 discussion 两节就够)
-
再读 2604.18071 理解当前实践的分布
-
最后读 2604.25850,因为它提出的问题(Harness 能不能自动进化)是 2026-2027 年最活跃的研究方向
-
然后从 2605.18747 的 GitHub 论文列表里挑 3-5 篇你最感兴趣的精读
如果这三篇只选一篇读,我选 AHE(2604.25850)。不是因为它的结果最漂亮,而是因为它提出了一个可以持续复用的方法框架——可观测性驱动的闭环改进。这个思路不只能用在 Harness Engineering 上,任何需要“边跑边改”的系统设计都可能用得上。
系列完结。 知识库文档里整理了全部参考文献链接,后续有新发现会持续补充。